No.11681 アンケート調査の集計方法 【社会人1年生】 2010/01/13(Wed) 12:07
これまでオール電化住宅を購入していただいたお客様120名を対象にアンケート調査をしています。
内容は,「毎月の電気使用量」と「節電を心がけたかどうかについて『○よくできた』『△まあまあできた』『×あまりできなかった』の3段階の自己申告」を回答してもらうというものです。
現在,『よくできた』と回答した家は,電気料金を抑えることができる,というふうに話を展開したいと思って,自己申告(○△×)の割合を出して,それぞれの電気使用量の平均を出しています。
しかし,自分でいろいろとアンケート調査や統計について調べてみると,標準偏差や誤差などがあることがわかり,単純に平均や割合を出すだけではダメだということがわかってきました。
ですが,具体的にどのようにすればいいのかがわかりません。
アドバイスをお願いします。
No.11683 Re: アンケート調査の集計方法 【青木繁伸】 2010/01/13(Wed) 13:42
自己申告の3群別の電気使用量の平均値に差があるかということですから,一元配置分散分析(または,ノンパラメトリック検定ならクラスカル・ウォリス検定)というところでしょう。
> 『よくできた』と回答した家は,電気料金を抑えることができる
電気料金を抑えることができたから『よくできた』と回答したということもあるかも
No.11685 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/13(Wed) 16:14
お返事ありがとうございます。
職場パソコンのエクセルデータ分析ツールには「一元配置分散分析」しかありませんでしたが,早速やってみました。
調べながらやったのですが,統計学は全くやったことがなく,まず「分散」とか「自由度」とか用語が全然わからないという状態です。
この「一元配置分散分析」の結果を元にアンケート調査を報告書にまとめるとすれば(グラフとか表も含めて),具体的にどのようにすればいいのでしょうか?
イメージとしては,誤差(?)とかを含めて,横軸に自己申告評価(○△×),縦軸に電気使用量をとって,グラフで相関関係を表現できればいいのではないかと思っているのですが,そのへんもアドバイスをお願いします。
No.11686 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/13(Wed) 16:32
大事なことを1つ忘れていましたが,今現在アンケートがなかなか回収できていない状況なんです。
アンケートが120人中50人くらいしか回収できないとしても,上記の話は成立するんでしょうか?
何度もすみませんが,よろしくお願いします。
No.11688 Re: アンケート調査の集計方法 【青木繁伸】 2010/01/13(Wed) 21:21
用語は google 等でも調べるとして,どのような計算が行われているかを一度は自分で計算してみるのも良いと思いますね。教科書を参照するのが一番良いでしょうけど,http://aoki2.si.gunma-u.ac.jp/lecture/Average/oneway-ANOVA.html などもちょっと見るのには便利。例題も付いていますしね。
データをどのようにまとめるかは,そのページの演習問題のところにある,表2のようにするのがオーソドックスかな?図で表す場合には,ボックス・アンド・ウィスカー(箱ひげ図;ボックス・プロット)http://aoki2.si.gunma-u.ac.jp/lecture/Dosuu/box-and-whisker.html とか。これも,「横軸に自己申告評価(○△×),縦軸に電気使用量をとって,グラフで相関関係を表現」ということの一つの表現法です。個々のデータを明示するグラフは,http://aoki2.si.gunma-u.ac.jp/R/dot_plot.html の下の方にあるグラフが参考になるでしょうか。
> 120人中50人くらいしか回収できない
と
いう場合には,回収できた50人くらいと回収できていない70人くらいに背景因子の違いがなければ(偏ったデータでなければ)「上記の話は成立する」ので
すが,そうでない場合には,結論を誤る可能性がありますね。例えば,うまくいった人たちの回答率は高いけど,うまくいかなかった人たちの回答率は低いよう
な場合,回収された人の結果は,調査対象者全体を反映しない可能性がありますね。
No.11697 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/14(Thu) 16:07
詳しい解説ありがとうございます。
これまで教えていただいたことは何とか理解できたと思いますが,また疑問が出てきました。
縦
軸に電気使用量,横軸に1〜12月を取り,月別の電気使用量の折れ線グラフを作って,「夏はエアコン使用により電気使用量が多くなるので,節電を心がけま
しょう」というふうに話を展開したいと考えています。そこで,月ごとに電気使用量の平均と標準偏差を取って,エラーバーで誤差をつけようと思いますが,こ
ういう場合も「一元配置分散分析」を行って,月ごとの電気使用量に違いがあるかどうかを検定したほうがよいのでしょうか?
他にもいくつかの項目で同様の比較を行おうと思っていますが,どういう場合に「一元配置分散分析」による検定を行うのかがまだよくわかりません。
回答よろしくお願いします。
No.11699 Re: アンケート調査の集計方法 【青木繁伸】 2010/01/14(Thu) 16:14
このデータは同じ家庭の1〜12月のデータが対象になる(対応のある)データでしょうか。
そのような場合には一元配置分散分析ではなく,乱塊法というのを使います。
http://aoki2.si.gunma-u.ac.jp/lecture/TwoWayANOVA/randblk.html の演習問題のデータ例と同じ構造になっているでしょう?
まあ,検定だどうだと面倒なことを言わないならば,月ごとの平均値を示して(グラフでも表でも),そこからわかることを述べるというのが,利用者(顧客)にもわかりやすいのだとは思います。
No.11700 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/14(Thu) 17:37
早速の回答ありがとうございます。
>このデータは同じ家庭の1〜12月のデータが対象になる(対応のある)データでしょうか。
同じ家庭ではなく,最初にお話した120の家庭を対象にしたバラバラのデータです。
リンク先の演習問題を見て,なんとなく違うというのはわかりますが,明確に「一元配置分散分析」と「乱塊法」の違いはまだよくわかりません。
>検定だどうだと面倒なことを言わないならば,月ごとの平均値を示して(グラフでも表でも),そこからわかることを述べるというのが,利用者(顧客)にもわかりやすいのだとは思います。
実は顧客だけが対象ではなく行政も関係しているので,「検定」とか「誤差」をしっかり考慮したほうがいいのかなと思っています。どうすればいいでしょうか?
No.11701 Re: アンケート調査の集計方法 【青木繁伸】 2010/01/14(Thu) 17:56
> 同じ家庭ではなく,最初にお話した120の家庭を対象にしたバラバラのデータです。
データが次のようになっていると対応のあるデータで,乱塊法になります。

以下のようになっているなら対応のないデータで一元配置分散分析です。月ごとのデータ数は同じでないこともあり,別の対象のデータから成り立っています。

両者が混在している,つまり,数世帯について数ヶ月分のデータが混じっている(世帯によって,何ヶ月ぶんのデータかというのも違うこともある)となると,困ったことになります。何らかの方針で,データを整理しなくてはいけないことになるでしょう。
> 行政も関係しているので,「検定」とか「誤差」をしっかり考慮したほうがいいのかなと思っています。
そのようなことでしたら,ちゃんと検定を行うようにしましょう。
No.11702 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/15(Fri) 10:21
何度もありがとうございます。
「乱塊法」と「一元配置分散分析」の違いがよくわかりました。と同時に,私の質問が説明不足なこともよくわかりました…。私のやろうとしていることは,「乱塊法」のほうです。
詳しく解説していただいて,検定については自分なりにだいぶ理解できたと思います。ですが,まだ「誤差」の扱いがよくわかりません。
最後に,今回の調査の場合「誤差」についてはどのようにすればよいかを教えていただければありがたいです。平均値に標準偏差を考慮するだけでよいのでしょうか?
No.11703 Re: アンケート調査の集計方法 【青木繁伸】 2010/01/15(Fri) 10:37
何の「誤差」なのでしょうか?
標準偏差はデータのバラツキを表現するもので,データが正規分布に従うなら
「平均値±1.96標準偏差の範囲にデータのほぼ95%が含まれる」ということがわかるというような使われ方をします。データが正規分布に従わないなら
ば,「数値1〜数値2の範囲にデータのほぼ95%が含まれる」というような数値を求める必要があるでしょう(下と上からそれぞれ2.5%に対応する値を求
める)。
(標本)調査を何回も行うと標本平均もその都度異なった値が得られます。この標本平均の標準偏差のことを特に標準誤差といいます。標準誤差は,母平均の信頼区間を求めることなどに使われます。「母平均の95%信頼区間は数値a〜数値bの範囲である」というように。
No.11704 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/15(Fri) 12:16
またまた説明不足な質問をしてしまい,失礼いたしました。
エクセルを使ってるのですが,グラフの「誤差範囲」を設定する項目に「標準偏差」や「標準誤差」があるので,わかりやすいほうの「標準偏差」を「誤差」として使おうと考えていました。
今回のアンケート調査は年に1回の調査で標準誤差は求められないと思いますし,電気使用量というものが正規分布として扱えるのかどうかもよくわかりません。
一言で「誤差」といってもいろいろあるということなので,このアンケート調査ではどのようにしたらよいでしょうか?
No.11705 Re: アンケート調査の集計方法 【青木繁伸】 2010/01/15(Fri) 12:52
> 今回のアンケート調査は年に1回の調査で標準誤差は求められないと思いますし
標本平均の標準誤差は,1回の調査だけから推定されます。不偏分散をU, データ数をnとすると,U/n の平方根ですよ。
利用法は,母平均の信頼区間:http://aoki2.si.gunma-u.ac.jp/lecture/Average/Mean2.html
> 一言で「誤差」といってもいろいろあるということなので,このアンケート調査ではどのようにしたらよいでしょうか?
どういう意味の誤差を考えるかによるでしょう
> エクセルを使ってるのですが,グラフの「誤差範囲」を設定する項目に「標準偏差」や「標準誤差」があるので,わかりやすいほうの「標準偏差」を「誤差」として使おうと考えていました。
なるほど,「エラーバーで誤差をつけようと思いますが」と書いてありましたね。「エラーバーを標準誤差で表すか標準偏差で表すか」と書いてあればすぐわかったのですけど(エクセルが使っている用語は,不完全,意味不明,誤用の場合がありますから注意)。
グ
ラフにエラーバーをつけるときにも,標準偏差でつけるか標準誤差でつけるかは,意味が変わってきます。ただ,エラーバー付きのグラフを見てその元になって
いるのが標準偏差か標準誤差かを明示してあっても,それを見た人が正しく解釈できているかどうかは怪しいものです。標準誤差は上の定義式から見てもわかる
ように 「n の平方根分の1」1/sqrt(n)
になっているので,標準偏差よりは小さい。で,見た目は「誤差が小さいように見える」ことから,標準誤差に基づいたエラーバーをつけようとする人が後を絶
たないという状況です。本来はちゃんと意味が違うのですけどね。
そういうことを踏まえて,「お好きな方を」といっておきましょう。
No.11706 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/15(Fri) 14:24
ご丁寧に何度も教えてくださり,本当にありがとうございました。
この方向で報告書をまとめたいと思います。
今後また質問をすることになるかもしれませんが,そのときもまた教えていただければ幸いです。
No.11821 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/25(Mon) 13:50
先日はどうもありがとうございました。
現在アンケートの集計作業と報告書作成を行っているところですが,またまた疑問点が出てきてしまいました。
電気使用量と自己申告評価(○△×)の関係については,一元配置分散分析で違いを検定するということを教えていただきましたが,自己申告評価(○△×)だけでの検定というのもできるのでしょうか?
例えば,100人から回答をもらったとして,○は37人(37%),△は33人(33%),×は30(30%)という結果になった場合,違いがあるということを言うために,検定を行うということはあるのでしょうか?(そもそもそういう検定があるのでしょうか?)
回答よろしくお願いします。
No.11822 Re: アンケート調査の集計方法 【青木繁伸】 2010/01/25(Mon) 14:12
> ○は37人(37%),△は33人(33%),×は30(30%)という結果になった場合,違いがあるということを言う
「違いがある」というのは,人数に違いがあるということですね。○,△,×がそれぞれ33人ずつくらいなら差がないということでしょう?これは,適合度の検定というのがあります。
http://aoki2.si.gunma-u.ac.jp/lecture/GoodnessOfFitness/nominalscale.html
この例を見るとわかるように,違いがあるというのは,理論分布と違いがあるということで,理論分布は「どれも同じ」というのもありますが,それは「a:b:cになる(a,b,c はさまざま)」の特別な場合であるということがわかります。
No.11826 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/26(Tue) 10:03
おはようございます。
早速の回答ありがとうございます。
ネットで調べてみたら,「X2(カイ二乗)適合度検定」というような表記もありましたが,これは「X2(カイ二乗)検定」と同じもの(公式や解き方など)と考えてもよいのでしょうか?
また例題ではサイコロや遺伝法則のように決まった確率や比率がありますが,このような法則性のないアンケートの調査の場合でも,○,△,×はそれぞれ1/3の確率という考え方でよいのでしょうか?
回答よろしくお願いします。
No.11827 Re: アンケート調査の集計方法 【青木繁伸】 2010/01/26(Tue) 10:15
なんでもカイ二乗検定という名前でひっくくるのではなく,
http://aoki2.si.gunma-u.ac.jp/lecture/GoodnessOfFitness/nominalscale.html
は適合度の検定ですし,
http://aoki2.si.gunma-u.ac.jp/lecture/Cross/cross.html
は独立性の検定です。おなじくカイ二乗分布を使いますけど,検定統計量を求める計算式は違います(期待値と観察値の乖離を評価するという点で根本的には同じなんですけどね)。
「法則性がない」のではなく,その分布にどのような理論分布を当てはめるかをあなたが決めないといけないのです。どれも同じ割合のはずだということなら 1/3 ずつですし,○は△,×の2倍あるはずというなら,2:1:1 でしょうし。
No.11846 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/26(Tue) 16:49
回答ありがとうございます。
自分で割合を決めるんですか!?
それだとアンケート調査では,都合のいいように割合を決めて(違いが出るように),適合度の検定を行って,違いが出ましたっていうこともできるわけですよね?
ということは,このようなアンケート調査では,この検定は適さないということでしょうか?
それとも何か割合を決められるような要素がどこかにあるのでしょうか?
No.11849 Re: アンケート調査の集計方法 【青木繁伸】 2010/01/26(Tue) 17:47
> 都合のいいように割合を決めて
都合のいいように決めた割合と差があるといっても,なんの効用もないでしょう?
> それとも何か割合を決められるような要素がどこかにあるのでしょうか?
それがあるかどうか,あるとしたらどのようなものかは,あなたにしかわからないでしょう。
No.11855 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/27(Wed) 16:12
う〜ん,むずかしいですね…。
何度も何度もどうもありがとうございました。
No.11889 Re: アンケート調査の集計方法 【社会人1年生】 2010/01/29(Fri) 10:35
何度も恐縮ですが,またまた疑問が出てきてしまいました。
「節電を心がけたかどうかについて『○よくできた』『△まあまあできた』『×あまりできなかった』の3段階の自己申告」を回答してもらうというアンケート調査ですが,節電についてさらに項目がわかれる場合は,どういう検定があるのでしょうか?
具
体的には,すべての家庭が,「A不要な照明の消灯」「B冷暖房の控えめな温度設定」「C家電製品の待機電力削減」の3つの項目すべてについて,どれだけ心
がけているかを『○よくできた』『△まあまあできた』『×あまりできなかった』の3段階の自己評価をしてもらい,例えば,「節電行動のうちAは○が多いが
Cは×が多い」というような傾向をみる場合です。
紹介していただいた独立性の検定と似ているような気もするのですが,すべての家庭が3つの項目すべてに答えるという点で違うような気がするのですが,どうなのでしょうか?
よろしくお願いします。
No.11896 Re: アンケート調査の集計方法 【青木繁伸】 2010/01/29(Fri) 13:30
マクネマー検定
http://aoki2.si.gunma-u.ac.jp/lecture/Hiritu/McNemar-test.html
の後半「マクネマー検定の拡張」を参照してみてください。
以
下のような集計表をつくり検定します。A:B, A:C, B:C の 3 通りやるので,多重比較と言うことになりますが,例えば全体の有意水準を
0.05 で行うとすれば,ボンフェローニ法による多重比較は,3 つの検定を有意水準 0.05/3 = 0.0166666
で行えばよいことになります。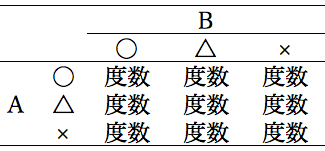
No.11911 Re: アンケート調査の集計方法 【社会人1年生】 2010/02/01(Mon) 17:30
遅くなってしまいましたが,回答ありがとうございました。
検定っていろいろあってむずかしいですね…。
もし項目がABCDEと増えていくと,20通りの検定を行う必要があるということですよね?
これはエクセルで計算えきるのでしょうか?
No.11916 Re: アンケート調査の集計方法 【青木繁伸】 2010/02/01(Mon) 22:09
> 項目がABCDEと増えていくと,20通りの検定
5 項目から 2 項目を取り出す取り出し方は 5C2=10 通りですよ(全部列挙してみればわかります)
> これはエクセルで計算えきるのでしょうか?
できるでしょう。
た
だ,計算の煩雑さとか,全ての計算をまちがいなく行えるかどうかとかは保証の限りでないでしょう。VBA
でも使えれば,自分でプログラムを書けば,どんな複雑な大量の計算でもできますよ。ただ,プログラミングをまず習ってからと言うことなら,大変さは大して
変わらないでしょうね。でも,いずれにしても Excel でやるというのは,不適切な選択でしょうね。Excel
はこのような仕事をするようには作られていません。R や perl などを使うのをお勧めします。
ところで,このスレッドもずいぶん長くなり,他の利用者にとって見れば,やっかいな存在になっていることでしょう。新たな質問(関連するものであっても)は,新たなスレッドを起こしてください。
● 「統計学関連なんでもあり」の過去ログ--- 043 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る