No.20561 正規分布でない、等分散でない群の解析 【とも】 2013/11/24(Sun) 14:38
いつもこのサイトで勉強させていただいています。
実験で以下のようなデータが得られました。
縦軸は反応速度で横軸は無処理とそれに対する処理(処理の時間)です。
処理の時間を長くすると一定値に収まるが,それまではばらつくといった結果です。
こ
の結果について,どの水準から無処理区と有意な差が生じているかを検定したのですがTukey-kramerは使えないため,Steel-Dwass,
Kruskal-Wallis
で行ったところ,あまり検出力が良くありませんでした。このようなデータを扱う場合にはどのような解析法が適切なのでしょうか。ご教授いただけると幸いで
す。
0
0 0 0 0
0 0 0 0
0 0 0 0 0
0 0 0
0 0
0 0
0 0
0 0 0 0
0 0
0 0
0
0 0 0 0
0 0 0
0 0 0
c t-1 t-2 t-3 t-4 t-5
No.20567 Re: 正規分布でない,等分散でない群の解析 【斜界人】 2013/11/25(Mon) 22:56
全対比較を行なったのですか? 対照との比較だけに興味があるなら,仮説を絞ったやり方が良いのではないでしょうか。順序性があるようなので多分
http://aoki2.si.gunma-u.ac.jp/R/Shirley-Williams.html
でしょうか。
水準の順序を気にしないなら,
http://aoki2.si.gunma-u.ac.jp/R/Steel.html
Dunnettで順位和検定統計量も使えるんじゃなかったかな。
仮説族を小さくすればMann-Whitneyの繰返しにBonferroni型補正でもそこそこかと。
ところで,データの状態がよく分からないのですが,同じ高さのoは同じ値で,標本の大きさはn=10で揃っていると考えて良いのでしょうか?
例えば,
c t1 t2 t3 t4 t5
1 12 6 3 1 1 1
2 13 8 5 2 2 2
3 14 9 6 3 3 3
4 12 11 7 5 4 7
5 12 12 10 7 7 2
6 13 13 11 8 10 7
7 12 14 12 9 11 3
8 12 15 13 12 12 2
9 14 6 14 13 3 7
10 12 8 13 14 11 2
ですか?
これだとMann-WhitneyでBonferroni補正した全対比較でも,少なくとも対照とt5の比較では検出力不足になるとは思えないのですが。
実際は何十もの水準があって全ての対比較をやりたいとか,標本がもっと小さいとかだと,どうすべきかは分からないです(どうしようもないかも)。
No.20568 Re: 正規分布でない,等分散でない群の解析 【とも】 2013/11/27(Wed) 07:47
ご回答ありがとうございます。
>同じ高さのoは同じ値で,標本の大きさはn=10で揃っていると考えて良いのでしょうか?
はい。その通りです。わかりにくくてすいません。
対照とt5の比較では有意な差が認められるのですが,対照とt1では,処理によって分散に差が生じているように見えるにもかかわらず,差が無いと出てしまうのでもっといい検定方法がないかと思案しているところです。
Shirley-Williams
Dunnett
Mann-WhitneyでBonferroni補正
試してみます。
ありがとうございました。
No.20574 Re: 正規分布でない,等分散でない群の解析 【斜界人】 2013/11/27(Wed) 20:59
もう見ていないかもしれませんが。
先ずお詫びです。忘れてましたがMann-Whitneyは等分散仮定です。並べ替え検定の方が良いかも。すみません。
分散も考えるなら別途尺度の検定を行なうか,位置と尺度ひっくるめて良ければ分布の差の検定も考えられます。
尺度の差の検定はMoodとかAnsari-Bradleyとか色々。n=10だと検出力が足りないかも。
分布の差の検定はKolmogorov-SmirnovとかLepageとか。有意でも位置が違うのか分散が違うのか両方違うのかは分からないです。
多分何れもBonferroni等で水準補正が必要です。
検出力が足りない理由としては,標本が小さい割に
・水準が多い -> 部分帰無仮説が多く個々の検出力が下がる
・同順位が多い -> 効率低下
が考えられます。
参考までに,No.20567のデータを使って対照vs.処理を対比較すると
Kolmogorov-Smirnov,Lepageだと,t3, t4, t5でp<0.05(対照と分布が異なる)。
Mann-Whitneyだと,t3, t4, t5でp<0.05(対照と位置が異なる)。
並べ替え検定は,t2, t3, t4, t5でp<0.05(対照と位置が異なる)。
MoodとAnsari-Bradleyでは全てp>0.05(対照と尺度が異なるとは言えない)。
(註)全てBonferroni-Holm補正した多重検定
No.20575 Re: 正規分布でない,等分散でない群の解析 【青木繁伸】 2013/11/27(Wed) 21:25
ちゃんとした決着を付けるためには,原データを提示する方がよいのではないでしょうか?
抽象論では結論づけられませんでしょう。
No.20577 Re: 正規分布でない,等分散でない群の解析 【とも】 2013/11/28(Thu) 09:25
斜界人 様
青木 様
アドバイスありがとうございます。
データを見て検討いただけると助かります。
質問として出したものはデータ数が揃っていたケースですが,データ数が揃っていないものが多いので,そちらを出します。
できれば無処理区との比較だけでなく,区間比較も行いたいです。
No.20581 Re: 正規分布でない,等分散でない群の解析 【とも】 2013/11/28(Thu) 11:34
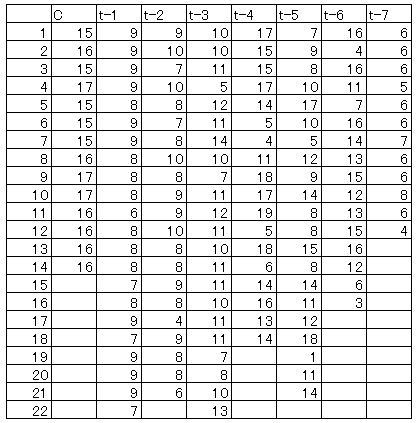
データをうまく貼り付けられませんでしたので
画像で貼り付けます。すいません。 C t-1 t-2 t-3 t-4 t-5 t-6 t-7
1 15 9 9 10 17 7 16 6
2 16 9 10 10 15 9 4 6
3 15 9 7 11 15 8 16 6
4 17 9 10 5 17 10 11 5
5 15 8 8 12 14 17 7 6
6 15 9 7 11 5 10 16 6
7 15 9 8 14 4 5 14 7
8 16 8 10 10 11 12 13 6
9 17 8 8 7 18 9 15 6
10 17 8 9 11 17 14 12 8
11 16 6 9 12 19 8 13 6
12 16 8 10 11 5 8 15 4
13 16 8 8 10 18 15 16
14 16 8 8 11 6 8 12
15 7 9 11 14 14 6
16 8 8 10 16 11 3
17 9 4 11 13 12
18 7 9 11 14 18
19 9 8 7 1
20 9 8 8 11
21 9 6 10 14
22 7 13
No.20586 Re: 正規分布でない,等分散でない群の解析 【青木繁伸】 2013/11/28(Thu) 13:35
3 回目,直したけど…
<pre>〜</pre> を使えばよいだけ(<,>は半角)
あるいはもっとよいのは,件のデータ行列を転置して,各区を行にカンマで区切って入力する
C: 15, 16, 15, …16
*
t-7: 6,6,6,5,6,…4
そうやれば,R に読み込むのも簡単C <- c(15, 16, 15, 17, 15, 15, 15, 16, 17, 17, 16, 16, 16, 16)
t.1 <- c(9, 9, 9, 9, 8, 9, 9, 8, 8, 8, 6, 8, 8, 8, 7, 8, 9, 7, 9, 9, 9, 7)
t.2 <- c(9, 10, 7, 10, 8, 7, 8, 10, 8, 9, 9, 10, 8, 8, 9, 8, 4, 9, 8, 8, 6)
t.3 <- c(10, 10, 11, 5, 12, 11, 14, 10, 7, 11, 12, 11, 10, 11, 11, 10, 11, 11, 7, 8, 10, 13)
t.4 <- c(17, 15, 15, 17, 14, 5, 4, 11, 18, 17, 19, 5, 18, 6, 14, 16, 13, 14)
t.5 <- c(7, 9, 8, 10, 17, 10, 5, 12, 9, 14, 8, 8, 15, 8, 14, 11, 12, 18, 1, 11, 14)
t.6 <- c(16, 4, 16, 11, 7, 16, 14, 13, 15, 12, 13, 15, 16, 12, 6, 3)
t.7 <- c(6, 6, 6, 5, 6, 6, 7, 6, 6, 8, 6, 4)
No.20587 Re: 正規分布でない,等分散でない群の解析 【とも】 2013/11/28(Thu) 14:17
青木先生,ご面倒をおかけします。
こんな感じでいいのでしょうか
C: 15,16,15,17,15,15,15,16,17,17,16,16,16,16,
t-1: 10,10,11,5,12,11,14,10,7,11,12,11,10,11,11,10,11,11,7,8,10,13,
t-2: 9,10,7,10,8,7,8,10,8,9,9,10,8,8,9,8,4,9,8,8,6,
t-3: 9,9,9,9,8,9,9,8,8,8,6,8,8,8,7,8,9,7,9,9,9,7,
t-4: 17,15,15,17,14,5,4,11,18,17,19,5,18,6,14,16,13,14,
t-5: 7,9,8,10,17,10,5,12,9,14,8,8,15,8,14,11,12,18,1,11,14,
t-6: 16,4,16,11,7,16,14,13,15,12,13,15,16,12,6,3,
t-7: 6,6,6,5,6,6,7,6,6,8,6,4
No.20588 Re: 正規分布でない,等分散でない群の解析 【青木繁伸】 2013/11/28(Thu) 18:22
代表値の差の多重比較(pairwise.t.test の改造)
http://aoki2.si.gunma-u.ac.jp/R/m_multi_comp2.html
により,以下の結果を得る。
どれが一番よいか?> C <- c(15, 16, 15, 17, 15, 15, 15, 16, 17, 17, 16, 16, 16, 16)
> t.1 <- c(9, 9, 9, 9, 8, 9, 9, 8, 8, 8, 6, 8, 8, 8, 7, 8, 9, 7, 9, 9, 9, 7)
> t.2 <- c(9, 10, 7, 10, 8, 7, 8, 10, 8, 9, 9, 10, 8, 8, 9, 8, 4, 9, 8, 8, 6)
> t.3 <- c(10, 10, 11, 5, 12, 11, 14, 10, 7, 11, 12, 11, 10, 11, 11, 10, 11, 11, 7, 8, 10, 13)
> t.4 <- c(17, 15, 15, 17, 14, 5, 4, 11, 18, 17, 19, 5, 18, 6, 14, 16, 13, 14)
> t.5 <- c(7, 9, 8, 10, 17, 10, 5, 12, 9, 14, 8, 8, 15, 8, 14, 11, 12, 18, 1, 11, 14)
> t.6 <- c(16, 4, 16, 11, 7, 16, 14, 13, 15, 12, 13, 15, 16, 12, 6, 3)
> t.7 <- c(6, 6, 6, 5, 6, 6, 7, 6, 6, 8, 6, 4)
> x <- c(C, t.1, t.2, t.3, t.4, t.5, t.6, t.7)
> g <- rep(0:7, c(length(C), length(t.1), length(t.2), length(t.3), length(t.4),
length(t.5), length(t.6), length(t.7)))
> pairwise.wilcox.test(x, g, p.adjust.method="holm")
Pairwise comparisons using wilcoxon tests
data: x and g
0 1 2 3 4 5 6
1 7.4e-09 - - - - - -
2 1.1e-08 1.00000 - - - - -
3 7.4e-09 0.00052 0.00202 - - - -
4 1.00000 0.02524 0.02236 0.05785 - - -
5 0.00033 0.09686 0.13878 1.00000 0.28650 - -
6 0.01482 0.05785 0.05785 0.19205 1.00000 1.00000 -
7 2.6e-06 2.7e-05 0.00057 3.4e-05 0.02585 0.00088 0.02210
P value adjustment method: holm
> pairwise.wilcox.test(x, g, p.adjust.method="hochberg")
Pairwise comparisons using wilcoxon tests
data: x and g
0 1 2 3 4 5 6
1 7.1e-09 - - - - - -
2 1.1e-08 0.92738 - - - - -
3 7.1e-09 0.00052 0.00202 - - - -
4 0.74717 0.02524 0.02236 0.05467 - - -
5 0.00033 0.09686 0.13878 0.92738 0.28650 - -
6 0.01482 0.05467 0.05467 0.19205 0.74717 0.74717 -
7 2.6e-06 2.7e-05 0.00057 3.4e-05 0.02585 0.00088 0.02210
P value adjustment method: hochberg
> pairwise.wilcox.test(x, g, p.adjust.method="hommel")
Pairwise comparisons using wilcoxon tests
data: x and g
0 1 2 3 4 5 6
1 6.8e-09 - - - - - -
2 1.1e-08 0.92738 - - - - -
3 6.8e-09 0.00047 0.00202 - - - -
4 0.61357 0.02163 0.01788 0.04821 - - -
5 0.00030 0.08610 0.12144 0.92738 0.28650 - -
6 0.01220 0.05381 0.05075 0.16712 0.61745 0.74717 -
7 2.6e-06 2.6e-05 0.00054 3.4e-05 0.02188 0.00088 0.01777
P value adjustment method: hommel
> pairwise.wilcox.test(x, g, p.adjust.method="bonferroni")
Pairwise comparisons using wilcoxon tests
data: x and g
0 1 2 3 4 5 6
1 7.4e-09 - - - - - -
2 1.2e-08 1.00000 - - - - -
3 7.4e-09 0.00070 0.00314 - - - -
4 1.00000 0.05048 0.04173 0.13499 - - -
5 0.00041 0.30135 0.48574 1.00000 1.00000 - -
6 0.02441 0.15308 0.14211 0.76821 1.00000 1.00000 -
7 2.9e-06 3.2e-05 0.00080 4.1e-05 0.05569 0.00129 0.03867
P value adjustment method: bonferroni
> pairwise.wilcox.test(x, g, p.adjust.method="BH")
Pairwise comparisons using wilcoxon tests
data: x and g
0 1 2 3 4 5 6
1 3.7e-09 - - - - - -
2 4.0e-09 0.81345 - - - - -
3 3.7e-09 8.7e-05 0.00029 - - - -
4 0.23051 0.00337 0.00298 0.00789 - - -
5 5.9e-05 0.01507 0.02313 0.92738 0.05813 - -
6 0.00203 0.00806 0.00789 0.03492 0.23051 0.26821 -
7 7.2e-07 6.3e-06 8.8e-05 6.9e-06 0.00348 0.00013 0.00297
P value adjustment method: BH
> pairwise.wilcox.test(x, g, p.adjust.method="BY")
Pairwise comparisons using wilcoxon tests
data: x and g
0 1 2 3 4 5 6
1 1.4e-08 - - - - - -
2 1.6e-08 1.00000 - - - - -
3 1.4e-08 0.00034 0.00112 - - - -
4 0.90527 0.01322 0.01171 0.03100 - - -
5 0.00023 0.05917 0.09084 1.00000 0.22828 - -
6 0.00799 0.03164 0.03100 0.13713 0.90527 1.00000 -
7 2.8e-06 2.5e-05 0.00035 2.7e-05 0.01367 0.00051 0.01168
P value adjustment method: BY
> pairwise.wilcox.test(x, g, p.adjust.method="fdr")
Pairwise comparisons using wilcoxon tests
data: x and g
0 1 2 3 4 5 6
1 3.7e-09 - - - - - -
2 4.0e-09 0.81345 - - - - -
3 3.7e-09 8.7e-05 0.00029 - - - -
4 0.23051 0.00337 0.00298 0.00789 - - -
5 5.9e-05 0.01507 0.02313 0.92738 0.05813 - -
6 0.00203 0.00806 0.00789 0.03492 0.23051 0.26821 -
7 7.2e-07 6.3e-06 8.8e-05 6.9e-06 0.00348 0.00013 0.00297
P value adjustment method: fdr
> pairwise.wilcox.test(x, g, p.adjust.method="none")
Pairwise comparisons using wilcoxon tests
data: x and g
0 1 2 3 4 5 6
1 2.6e-10 - - - - - -
2 4.3e-10 0.78440 - - - - -
3 2.6e-10 2.5e-05 0.00011 - - - -
4 0.20452 0.00180 0.00149 0.00482 - - -
5 1.5e-05 0.01076 0.01735 0.92738 0.04775 - -
6 0.00087 0.00547 0.00508 0.02744 0.20582 0.24906 -
7 1.0e-07 1.1e-06 2.8e-05 1.5e-06 0.00199 4.6e-05 0.00138
P value adjustment method: none
No.20589 Re: 正規分布でない,等分散でない群の解析 【とも】 2013/11/28(Thu) 20:11
青木先生,解析までしていただきありがとうございます。
代表値の差の多重比較というのは考えていませんでした。
P値の補正方法による差の違いをみると"BH"と"fdr"が検出力が高いが,最も差が出やすいのは補正無しということで良いのでしょうか。
その場合cとt4,t1とt2,t3とt5,t4とt6,t5とt6の間は5%水準で有意差がないということでしょうか。
No.20590 Re: 正規分布でない,等分散でない群の解析 【青木繁伸】 2013/11/28(Thu) 22:03
> 最も差が出やすいのは補正無しということで良いのでしょうか。
補正なしというのは,多重性を考えないということですよ!
No.20592 Re: 正規分布でない,等分散でない群の解析 【とも】 2013/11/29(Fri) 08:00
青木先生,ご指摘ありがとうございます。
“補正無し”はt検定の繰り返しで,やってはいけないということですね。
ということは"BH"と"fdr"補正を採用すれば,差の検出力が高まるということでよいのでしょうか。
基本的なところがよく分かっていなくて申し訳ありません。
手元に「統計的多重比較法の基礎」がありますので勉強してみます。
No.20593 Re: 正規分布でない,等分散でない群の解析 【斜界人】 2013/11/29(Fri) 12:10
青木先生,フォローありがとうございます。
ともさん
五数要約,箱髭図も見直してみて下さい。
例えば,対照とその他の比較でt4だけ差が出ない理由も見当がつきますし,Cとt4は多分どの方法でも代表値の差は検出できないだろうと思えます。
箱髭図の他に
http://aoki2.si.gunma-u.ac.jp/R/dot_plot.html
のような図を描いてみるのもデータの把握には良いでしょう。
最初の質問についても,同様にデータを見直してみれば,
> 対照とt1では,処理によって分散に差が生じているように
> 見えるにもかかわらず,差が無いと出てしまう
理由が分かるでしょう。
ばらつきにも興味があると勘違いしたのですが,そうでなければ対照とt1で差が無いという結果も,おそらく正しいだろうと思われます。
No.20595 Re: 正規分布でない,等分散でない群の解析 【とも】 2013/11/30(Sat) 09:12
斜界人 様
アドバイスありがとうございます。
箱ひげ図は分布の概要を把握するのにいいと思いました。
また青木先生の群別データ分布図は,同じようなものをパワーポイントを使って作ろうと考えていたので,大変助かりました。
> ばらつきにも興味があると勘違いしたのですが
分散が異なるとパラメトリックな検定ができないため不等分散でも検出力の高い方法を探していたところです。
処理により分散が変化することは,何らかの影響を受けていると思われますので分散の差異とその要因についても詰めていきたいと考えています。
● 「統計学関連なんでもあり」の過去ログ--- 046 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る