No.20156 Re: ロジスティック回帰分析 【taipapa】 2013/08/26(Mon) 21:32
貴方が考えているのは以下の様なことでしょうか...
Rで,シミュレートしてみました.
> test.df <- data.frame(c(rep("A", 50), rep("B", 50)),round(c(rnorm(50, 60, 30),
+ rnorm(50, 60, 10)), 0), round(c(rnorm(50, 120, 30), rnorm(50, 130, 20)),0),
+ round(c(rnorm(50, 90, 20), rnorm(50, 95, 25))), round(c(rnorm(50, 20, 10),
+ rnorm(50, 20, 5)))) # 疾患タイプAとBそれぞれ50人で,年齢,LDL,血糖,BUNを測定(ほんの少しの差をつける)
> colnames(test.df) <- c("type", "age", "LDL", "glucose", "BUN")
> test.glm <- glm(type ~ age + LDL + glucose + BUN, family=binomial, data=test.df) # ロジスティック回帰を実行
> summary(test.glm)
………………………
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.531526 2.184434 -2.074 0.0380 *
age -0.009505 0.011225 -0.847 0.3971
LDL 0.024929 0.010146 2.457 0.0140 *
glucose 0.018422 0.010991 1.676 0.0937 .
BUN 0.012410 0.029502 0.421 0.6740
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
…………
> library(epicalc)
> logistic.display(test.glm)
Logistic regression predicting type : B vs A
crude OR(95%CI) adj. OR(95%CI) P(Wald's test) P(LR-test)
age (cont. var.) 0.989 (0.9697,1.0086) 0.9905 (0.969,1.0126) 0.397 0.388
LDL (cont. var.) 1.02 (1,1.04) 1.03 (1.01,1.05) 0.014 0.008
glucose (cont. var.) 1.01 (0.99,1.03) 1.02 (1,1.04) 0.094 0.086
BUN (cont. var.) 1 (0.95,1.05) 1.01 (0.96,1.07) 0.674 0.674
……………….
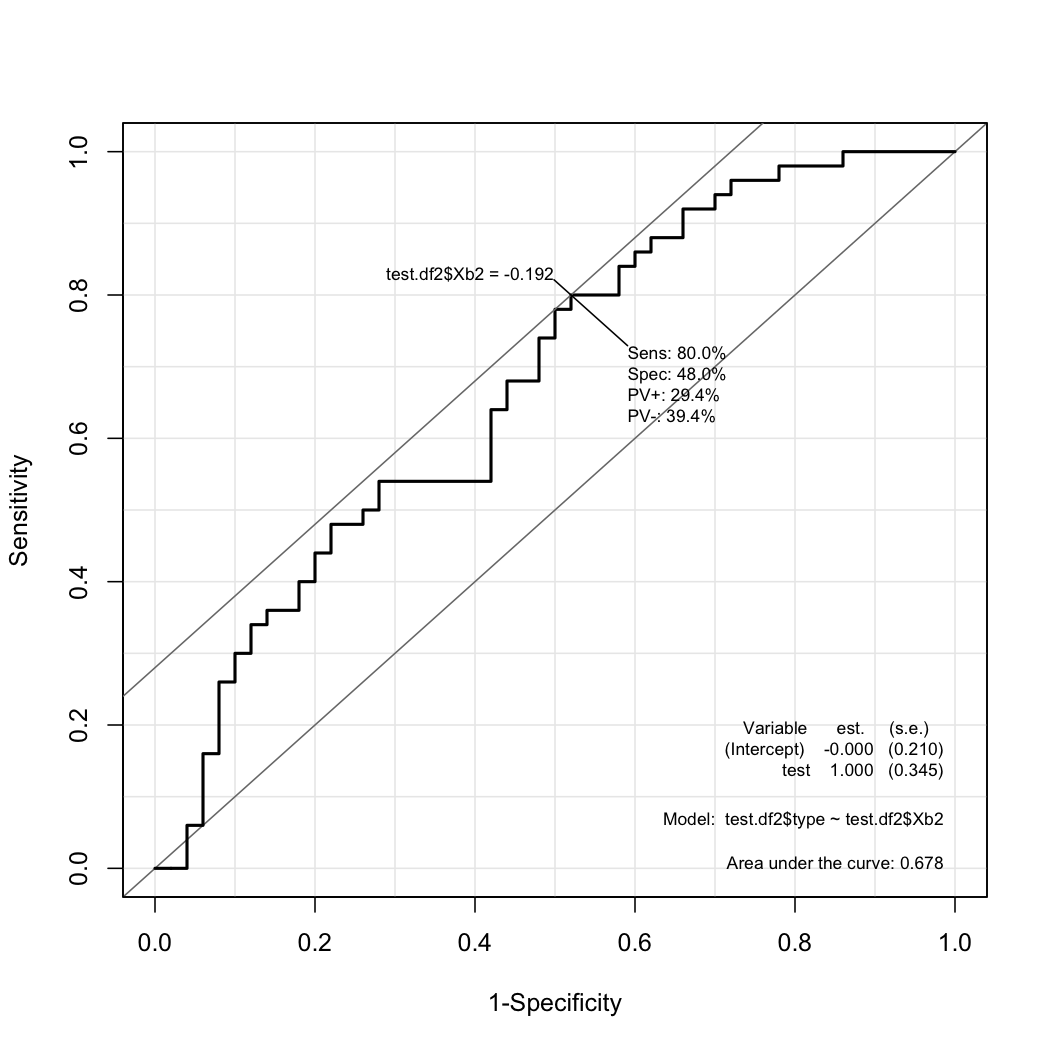
# type Bになる確率は,prpbabilityB = 1/(1+exp(-Xbeta))なので,上記のsummary(test.glm)の表のEstimatedから計算する
> test.df2$Xb <- -0.009505*test.df$age + 0.024929*test.df$LDL + 0.018422*test.df$glucose + 0.01241*test.df$BUN
> test.df2$Xb2 <- test.df2$Xb - 4.531526
> test.df2$probabilityB <- 1/(1 + exp(-(test.df2$Xb2)))
# これで,Bになる確率がtest.df2のコラムprobabilityBに入る.
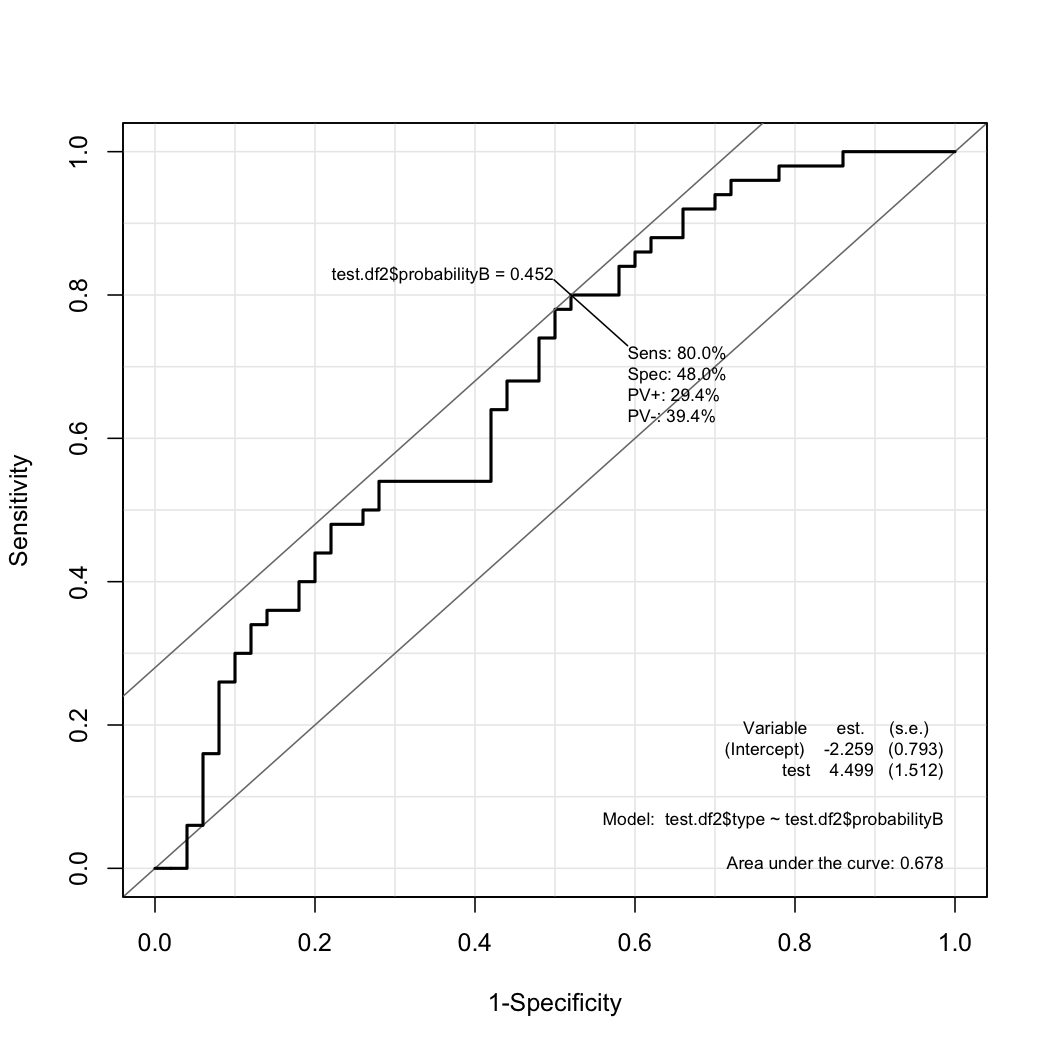
# この確率をもとに,ROC curveを書いてみる.
> library(Epi)
> ROC(test.df2$probabilityB, test.df2$type, plot="ROC")この程度の差に医学的な意味があるかどうかは,また,別の問題でしょうが...貴方のご希望にそっていますでしょうか?