No.12499 Re: どうしても正規性と等分散が仮定できない場合 【青木繁伸】 2010/04/20(Tue) 21:28
> modelの残差の正規性と分散の非均一性が仮定できないことになってしまいます。
あの,ですね。残差が正規分布するのではなく,「推定値の誤差が正規分布する」のじゃないですか?
単回帰分析において,平均値近辺の誤差は小さく,平均値から離れるにつれて誤差が大きくなるというのは常識では?直線回帰式(予測式)の全域において誤差が単一の正規分布に従うなんて事はないでしょう。
![]()
No.12481 Re: どうしても正規性と等分散が仮定できない場合 【青木繁伸】 2010/04/20(Tue) 07:36
No. 12314 のスレッドを参照してください。
重回帰分析に正規性の仮定は不要です。
しかも,「等分散性が」って,何と何の分散が等しいというのでしょう?
No.12483 Re: どうしても正規性と等分散が仮定できない場合 【きみか】 2010/04/20(Tue) 09:21
早速の回答ありがとうございます。
重回帰分析に,正規性の仮定は必要ないのですね。
ご回答,本当にありがとうございます。
重ね重ね,お手数をおかけ致しますが,もう一つ教えて頂けないでしょうか。
y~x*zの関係が,個体(A,B,C)によって異なることを示したいと思っております。
個体の効果(名義変数)をIDとしたとき,x*z*IDの交互作用が有意であることを示すために,どのような統計方法を行うのが妥当なのでしょうか。
重回帰分析(y~x*z*ID)を行うと,全ての係数は有意にゼロと異なるという結果になります。
た だ,自分では,個体によって,y~x*zの関係が異なることを示したい場合,3変数の交互作用(y*z*ID)をF値によって評価(分散分析)すれば良い のかと思っておりました。ただ,さきほどと同様の検定を用いると,正規分布と等分散は仮定できないという結果になります。
y値を予測したいわけではなく,yに対するx*zの関係が個体によって変わることを示したいのですが,結局,重回帰分析でも,分散分析でも,どちらでも示すことができるのでしょうか。
長文になってしまい,申し訳ありません。
よろしくお願い致します。
No.12487 Re: どうしても正規性と等分散が仮定できない場合 【波音】 2010/04/20(Tue) 10:11
重要なのは"誤差(残差)の"正規性です(回帰診断では残差の正規確率プロットが用いられる)。分散についても同様で,「等分散性」ではなくて「(残差の)分散の均一性」が重要なのです(回帰診断ではスチューデント化された残差プロットが用いられる)。
> x*z*IDの交互作用が有意であることを示すために,どのような統計方法を行うのが妥当なのでしょうか。
y ~ x * z * IDというのは3次の交互作用を含めたフルモデルですが,これも共分散分析(ダミー変数を用いた重回帰分析)です。たしかに,この3次の交互作用が有意ならば「個体によって,y~x*zの関係が異なる」ということが主張できるでしょう。
> 結局,重回帰分析でも,分散分析でも,どちらでも示すことができるのでしょうか。
(誤解を恐れずにいうならば)その通りです。summary(lm(y ~ x*z*ID))で係数表が出ますし,summary(aov(lm(y ~ x*z*ID)))で分散分析表が出ますからね。
No.12488 Re: どうしても正規性と等分散が仮定できない場合 【青木繁伸】 2010/04/20(Tue) 10:56
> 結局,重回帰分析でも,分散分析でも,どちらでも示すことができるのでしょうか。
しかり。
説明変数がカテゴリー変数のとき,二元配置分散分析のと重回帰分析の関係を以下の頁に示してあります。他の場合も同じような関係があり,同じ結果になるのです。
http://aoki2.si.gunma-u.ac.jp/lecture/TwoWayANOVA/TwoWay4.html
No.12498 Re: どうしても正規性と等分散が仮定できない場合 【きみか】 2010/04/20(Tue) 19:59
ご回答ありがとうございます。重回帰分析と分散分析でも,個体の効果によって,x*zが示せることができるのですね。青木先生,リンクありがとうございました。分散分析と重回帰分析の関係が少しわかりました(もっと勉強しなければなりません)。
波音さま,青木先生,言葉が足りなく,使い方が間違っていて申し訳ありませんでした。
model<-lm(y~x*z*ID)
shapiro.test(residuals(model))
ncv.test(model)
を 行った時,有意になり(P<0.05),modelの残差の正規性と分散の非均一性が仮定できないことになってしまいます。ただ,サンプルサイズが 非常に多く(1000~2000),modelの残差のヒストグラムも見た目には,正規分布に近いです。Normal q-qプロットにおいても,ほとんどの点が直線上にのっていますし,residualsとfitted valuesの関係も直線的で,fitted valuesが大きくなるほどresidualsがばらつくということは,とくにないです(あくまで見た目ですが)。
glmを適用する場 合は,可能なかぎり,Normal q-qプロットにおいて,なるだけ点が直線上にのるように,fitted valueにたいして,なるだけ残差が均一に分散するように,誤差構造(family)やlink funcitionを,いろいろ変えてやってみる,という方向でよろしいのでしょうか。
何度も,申し訳ありません。
No.12499 Re: どうしても正規性と等分散が仮定できない場合 【青木繁伸】 2010/04/20(Tue) 21:28
> modelの残差の正規性と分散の非均一性が仮定できないことになってしまいます。
あの,ですね。残差が正規分布するのではなく,「推定値の誤差が正規分布する」のじゃないですか?
単回帰分析において,平均値近辺の誤差は小さく,平均値から離れるにつれて誤差が大きくなるというのは常識では?直線回帰式(予測式)の全域において誤差が単一の正規分布に従うなんて事はないでしょう。
No.12500 Re: どうしても正規性と等分散が仮定できない場合 【青木繁伸】 2010/04/20(Tue) 21:51
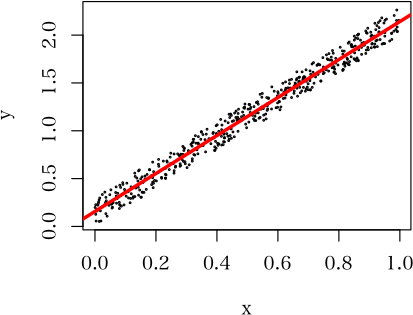
予測式は妥当で,しかし残差は正規分布に従わない例です。このような場合に回帰分析が不適切だとどこに書いてあるでしょうか?> n <- 500
> x <- runif(n)
> y <- x*2+runif(n)*0.3
> d <- data.frame(x, y)
> a <- lm(y~x, d)
> summary(a)
Call:
lm(formula = y ~ x, data = d)
Residuals:
Min 1Q Median 3Q Max
-0.153689 -0.073034 0.002584 0.070351 0.156626
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.156306 0.007574 20.64 <2e-16 ***
x 1.985393 0.012995 152.79 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.08325 on 498 degrees of freedom
Multiple R-squared: 0.9791, Adjusted R-squared: 0.9791
F-statistic: 2.334e+04 on 1 and 498 DF, p-value: < 2.2e-16
> shapiro.test(residuals(a))
シャピロ・ウィルクの正規性検定
データ: residuals(a)
W = 0.96, P値 = 2.087e-10
> plot(y~x, d, cex=0.2)
> abline(a, col="red", lwd=3)
No.12501 Re: どうしても正規性と等分散が仮定できない場合 【きみか】 2010/04/20(Tue) 22:29
青木先生,ご回答ありがとうございます。
本当に言葉の使いかたがなっていないし,きちんと理解できていなくて,申し訳ありません。
推定値の誤差とは,modelによって予測された推定値から,もとの値(従属変数)を引いたものですよね。それを残差と呼ぶのだと思っておりました。
>予測式は妥当で,しかし残差は正規分布に従わない例です。このような場合に回帰分析が不適切だとどこに書いてあるでしょうか?
例 題を示して頂き,ありがとうございます。不適切というよりも,誤差が正規分布に従っていた方がまし,なのだと思っておりました。線形最小二乗法 (Least square regression)は,誤差(error)が,正規分布していたときに,最も力を発揮するものだと思っていたのですが,そういうものでもないというこ とですよね?
お手数をおかけ致しました。
本当に,ありがとうございました。
● 「統計学関連なんでもあり」の過去ログ--- 043 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る