No.10526 エラーバーについて 【MIA】 2009/07/29(Wed) 20:16
初めまして。
すごく初歩的ですみませんが,エラーバーについて質問があります。
エラーバーに使われる指標にS.D.とS.E.が多いのはなぜでしょうか。
Cumming. G. et al.(2007). Error bar in experimental biology
によると,C.I.を使うことが20年ぐらい前から勧められているようです。
S.D.とS.E.が多いのはただ単に慣習だからでしょうか。
No.10528 Re: エラーバーについて 【青木繁伸】 2009/07/29(Wed) 21:49
> S.D.とS.E.が多いのはただ単に慣習だからでしょうか。
そうでしょう。しかも,S.D. と S.E. では,意味が全く異なる上,本当はこっちを使うべしといっている
> C.I.を使うことが20年ぐらい前から勧められているようです
も,エラーバーが重ならなければ差がある,なんて,間違ったことをいっている。2群それぞれの95%信頼区間のエラーバーが重なっていても,二群の平均値に差があることもちゃんとある。ということです。
http://aoki2.si.gunma-u.ac.jp/lecture/mb-arc/arc038/00236.html
要するに,エラーバーを付けるというのは,ちょっとした自己満足に過ぎないのですね。
No.10530 Re: エラーバーについて 【MIA】 2009/07/29(Wed) 23:18
さっそくのご返答ありがとうございました。
とても参考になりました。
Cummingの論文を読んで少し理解した気になっていました。
No.10532 Re: エラーバーについて 【波音】 2009/07/30(Thu) 13:27
> エラーバーが重ならなければ差がある,なんて,間違ったことをいっている。
実のところは不明ですが,もしかしたらこういう間違いをしている人は「差の標準誤差をエラーバーとして表示したとき,エラーバーが重ならないと有意に異なる」ということと取り違えているのかもしれません。
過去ログで青木先生が提示されている標準誤差のエラーバーは重なっていませんが,差の標準誤差:
SEdiff = sqrt(SE1^2 + SE2^2)
をエラーバーとして表示すると,たしかに2つのエラーバーは重ならない(検定の結果も有意である)のが確認できます。
# 過去ログにある通りにset.seed(987654)で発生させた乱数のデータを用いている
SEdiff <- sqrt(SE1^2 + SE2^2) # 差の標準誤差
plot(1:2, c(M1, M2), xlim=c(0, 3), ylim=c(40, 60), cex=1.5)
arrows(1, M1, 1, M1-SEdiff, angle=90) # 以下,差の標準誤差を誤差棒として表示
arrows(1, M1, 1, M1+SEdiff, angle=90)
arrows(2, M2, 2, M2-SEdiff, angle=90)
arrows(2, M2, 2, M2+SEdiff, angle=90)
abline(h=c(M1+SEdiff, M2-SEdiff), lty=2, col="red")
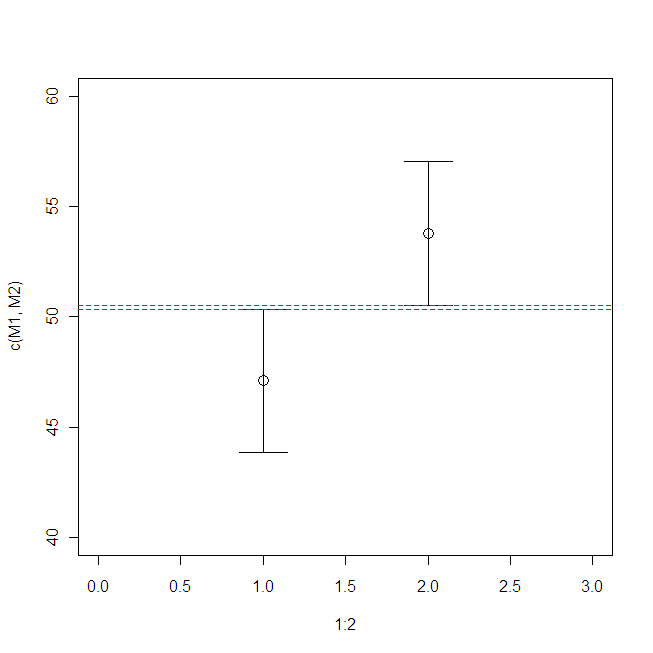
No.10533 Re: エラーバーについて 【MIA】 2009/07/30(Thu) 17:58
ご丁寧な回答,ありがとうございます。
No.10535 Re: エラーバーについて 【青木繁伸】 2009/07/30(Thu) 21:26
> 波音 さん No. 10532
> 「差の標準誤差をエラーバーとして表示したとき,エラーバーが重ならないと有意に異なる」ということと取り違えているのかもしれません。
> 差の標準誤差:
> SEdiff = sqrt(SE1^2 + SE2^2)
> をエラーバーとして表示すると,たしかに2つのエラーバーは重ならない(検定の結果も有意である)のが確認できます。
こ
の SEdiff
は,平均値の差が標準正規分布に従う(大標本のばあい)ですね。例では,二群のサンプルサイズと標準偏差が等しいので,近似値となります。さらに,2つの
平均値から± SEdiff するわけで,エラーバーが重ならないということは,片方の平均値±2*SEdiff
つまり信頼区間にもう一方の平均値が含まれないこととニアリーイコール。そのため,波音さんの図のエラーバーの間には隙間がある。例数が異なったり,標準
偏差が異なったりすると,単にエラーバーが重なっているかどうかで二群の平均値に差があるかどうかを表示するのは至難の業というか,無理では?
No.10536 Re: エラーバーについて 【takahashi】 2009/07/30(Thu) 22:46
http://www.latrobe.edu.au/psy/cumming/docs/Belia%20Fidler%20et%20al%20PM%2005rev.pdf
この論文にいろいろな誤解がまとまってた記憶があります。
内容はだいたい忘れましたが,たとえば対応のあるデータの時に,図示されるエラーバーは平均値の差に関して何の意味も持たない,とか。
No.10537 Re: エラーバーについて 【波音】 2009/07/31(Fri) 00:14
> 例数が異なったり,標準偏差が異なったりすると,単にエラーバーが重なっているかどうかで二群の平均値に差があるかどうかを表示するのは至難の業というか,無理では?
言葉足らずの説明でした。ご指摘の通り,このSEdiffは直交計画(つまりデータ数が同じ場合)のときに計算されるものです。そうでない場合には,これを使ってエラーバーの重なりで有意であるかどうか判断するのは適切ではありません。
こ
の方法が紹介されている"Alan Grafen and Rosie Hails. Modern Statistics for the Life
Sciences. Oxford University Press,
2008."でも,この方法は平均値の対比較にのみ分析者の目を向かせがちなので危険な方法である,と述べられています。
過去のスレッド: http://aoki2.si.gunma-u.ac.jp/lecture/mb-arc/arc038/00236.htmlを見て以来,私は1.96±標準偏差のエラーバーを描くのが好みとなっていますが,改めて考えるとエラーバーを図示するのはそれほど必須なものではないのかもしれません(^_^;)
ち
なみに,同書では標準偏差,標準誤差,差の標準誤差,信頼区間のいずれをか選ぶべきかについて,(1)その図でどのような情報を伝えたいのか,(2)どの
種類のエラーバーを用いて,それがどのような意味を示すのかを明示すべき,とあります(当たり前といえば当たり前ですが)。
● 「統計学関連なんでもあり」の過去ログ--- 042 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る