No.04203 Re: t検定について 【青木繁伸】 2007/08/21(Tue) 17:59
ヒストグラムはたとえば以下のようになっているのだが(クリックすると原寸表示)
No.04174 Re: t検定について 【青木繁伸】 2007/08/17(Fri) 20:14
> 検出力が高くなりすぎないように35個のデータを使用
検出力が高くなりすぎて困ることってあるんでしょうか?
既存のデータの一部を使うというのは,どうかと思います。
存在するデータで,どの程度の差が検出できるのかとか,そっち方面を攻めるべきでしょう。
分析に取り入れるデータの選別段階で,いろいろドロドロが入り込みそう。
No.04176 Re: t検定について 【@@社員】 2007/08/18(Sat) 00:00
永田靖さんの本で40〜50以上のデータがある場合は検定をするべきではないというようなことが書いてあったの で,(理由は本来は無視できるような差を検出してしまうからということだったと思います。)参考にしてみたのですが,確かに35のデータで検定したときと 200のデータで検定したときでは有意差のありなしに違いがでました。検定においてのサンプル数はどのようにして決めたらよいのでしょうか?何か参考文献 等あれば教えてください。よろしくお願いします。
No.04179 Re: t検定について 【青木繁伸】 2007/08/18(Sat) 05:59
> 永田靖さんの本で40〜50以上のデータがある場合は検定をするべきではないというようなことが書いてあった
どの本でしたかねえ?
言っていることは分かるが,一般的には受け入れにくいのでは?
> サンプル数はどのようにして決めたらよいのでしょうか
同じく,永田さんの本で,サンプルサイズの決め方とかいうタイトルの本があったと思いますが,今出先なのではっきり書けない。
No.04191 Re: t検定について 【@@社員】 2007/08/20(Mon) 18:46
統計的方法のP113にサンプルサイズが大きいことの弊害として「サンプルサイズが大きいと,検出力が大きくなっ て,実務的にほとんど意味のない違いでも検出してしまう確率が高くなるからである。」と書いてあります。確かにサンプルサイズが異なることで有意差のあり なしに違いが出てしまうので,どのように解釈したらよいのか教えてください。また,「検定はサンプルサイズが小さい場合のデータに対して行う統計推測の手 段である」とも書いてあります。
どう解釈したらよいのかアドバイスよろしくお願いします。
No.04192 Re: t検定について 【@@社員】 2007/08/20(Mon) 18:47
本のタイトルは「統計的方法のしくみ」です。
No.04201 Re: t検定について 【青木繁伸】 2007/08/21(Tue) 17:24
113,114ページですね
反論
サンプルサイズが大きいとはどの程度かというと,ヒストグラムを描いて分布型を考察できる程度ぐらいと考えておけばよい,つまり,n1とn2のそれぞれが約40〜50以上
40や50ではヒストグラムは描けるが(しかし,きれいなヒストグラムは描けないことが多い),目で見て平均値に差があるかどうか判断するのは難しい
形式的に検定を行って実務的に意味のない差を有意差ありと見なすよりも,点推定値を比較して考察する方がよい。
点推定値だけを考えるのではだめである。点推定値の標準誤差(実際には差の標準誤差)を考えないといけない。
差が実質的に意味があるかどうかは,検定を行う前に考えなければならない。実質的に意味がないなら検定を行う必要はない。実質的に意味があるなら,その差が偶然得られたのではないことを示さないといけない。それが,検定である。
検定を行うときの注意
http://aoki2.si.gunma-u.ac.jp/lecture/Kentei/caution.html
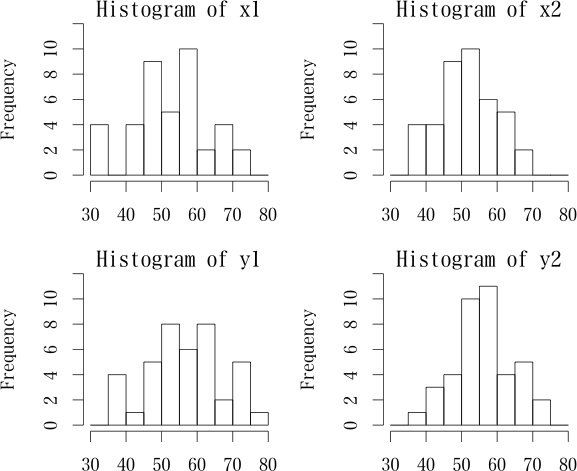
検定が必要であることは,以下のシミュレーション例を見れば分かる。x1とy1の平均値の差もx2とy2の平均値の差も同じく4であるが,x1,y1の標準偏差は共に10,x2,y2の標準偏差は8である。平均値の差の検定は当然ながら異なるものである。
平均値の差の検定を行わず,ヒストグラムを描いたり点推定値を比較したりだけで真理に迫れるだろうか?> set.seed(12345)
> x <- rnorm(40) # 標準正規分布に従う40個の数値データ
> x1 <- x*10+50 # 平均値50,標準偏差10
> y1 <- x*10+54 # 平均値54,標準偏差10 x1 を 4 だけ平行移動したもの
> t.test(x1, y1, var.equal=TRUE)
Two Sample t-test
data: x1 and y1
t = -1.7227, df = 78, p-value = 0.08891 # 有意な差であるとはいえない
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-8.6227233 0.6227233
sample estimates:
mean of x mean of y
52.40185 56.40185
> x2 <- x*8+50 # 平均値50,標準偏差8
> y2 <- x*8+54 # 平均値54,標準偏差8 x2 を 4 だけ平行移動したもの
> t.test(x2, y2, var.equal=TRUE)
Two Sample t-test
data: x2 and y2
t = -2.1533, df = 78, p-value = 0.03438 # 有意な差である
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-7.6981787 -0.3018213
sample estimates:
mean of x mean of y
51.92148 55.92148
No.04203 Re: t検定について 【青木繁伸】 2007/08/21(Tue) 17:59
ヒストグラムはたとえば以下のようになっているのだが(クリックすると原寸表示)
No.04210 Re: t検定について 【kai】 2007/08/22(Wed) 16:07
>永田靖さんの本で40〜50以上のデータがある場合は検定をするべきではないというようなことが書いてあったので,
永田さんの言いたい事は,データがたくさんある場合には検定のような“定性的な方法”を用いるのではなく,区間推定のような“定量的な方法”を用いた方が良いという意味だと思います.
データはたくさんあればあるほど,技術的な判断はしやすくなります.
検定では差があるという結果が出たとしても,それが技術的に有効な差なのかどうかはわかりません.
No.04214 Re: t検定について 【@@社員】 2007/08/23(Thu) 12:30
〉40や50ではヒストグラムは描けるが(しかし,きれいなヒストグラムは描けないことが多い),目で見て平均値に差があるかどうか判断するのは難しい
確かにおっしゃるとおりだと思います。
〉データがたくさんある場合には検定のような“定性的な方法”を用いるのではなく
検定は定性的な方法なのですか?勉強不足でぴんとこないのですが,教えてください。
よろしくお願いします。
No.04216 Re: t検定について 【青木繁伸】 2007/08/23(Thu) 14:35
定性的というのは,「有意である」か「有意ではない」かの2つの判断しかない(場合によっては「保留」せよという論も見たが)からでしょう。
区間推定なら,区間の幅,位置,区間に帰無仮説が仮定している数値が含まれるかどうかの情報が入っている。この情報は検定で得られる情報を含む(区間に帰無仮説が仮定している数値が含まれるかどうかの情報)。
よって,「検定を行うよりは区間推定を行いなさい。さらにはパワーアナリシスをすると良いでしょう」ということでしょう。
No.04217 Re: t検定について 【kai】 2007/08/23(Thu) 15:16
青木先生,フォローをありがとうございます.
検定では確率的に差があるかどうかを判断しているだけで,差が大きいかどうか(定量的に)は教えてくれないのです.
技 術的に考えて差があるという判断を下すためには,まず,これくらい差があったら差があるという判断を下すという基準を明確にし,差の区間推定をした結果そ の範囲の下限が基準以上であれば,技術的に考えても差があると判断出来ます.その範囲内に基準が入ってしまった場合は,差があるともないとも判断出来ない と言う事になります.基準が上限以上であれば差が無いという判断になります.
No.04237 Re: t検定について 【@@社員】 2007/08/24(Fri) 15:06
ありがとうございます。検定が定性的という意味がわかりました。
● 「統計学関連なんでもあり」の過去ログ--- 040 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る