> means <- sapply(data2, colMeans) > means 1 2 X1 3.5 7.5 X2 6.5 4.5 > d <- means[,1]-means[,2] > d X1 X2 -4 2
> S <- lapply(data2, function(x) var(x)*(nrow(x)-1)) > S $`1` X1 X2 X1 39.5 7.5 X2 7.5 21.5 $`2` X1 X2 X1 23.5 14.5 X2 14.5 33.5
> V <- (S[[1]]+S[[2]])/(nrow(data)-2) > V X1 X2 X1 6.3 2.2 X2 2.2 5.5
すなわち,判別式 $DF_0$ は,> a <- solve(V, d) > a X1 X2 -0.8856089 0.7178799
\[ DF_0 = -0.88561\ X_{1} + 0.71788\ X_{2} + c \] となる。
今の場合は,平均値の平均値は,$5.5$,$5.5$ なので,$DF_0 = - 0.92251$ となり,$c = 0.92251$ とする。
すなわち,最終的な判別関数は> c <- as.numeric(-a %*% rowMeans(means)) > c [1] 0.9225092
\[ DF = - 0.88561\ X_{1} + 0.71788\ X_{2} + 0.92251 \] となる。
| 群 | ケース | $X_{1}$ | $X_{2}$ | 判別値 | 判別群 |
|---|---|---|---|---|---|
| 1 | 1 | 5 | 10 | 3.67326 | 1 |
| 1 | 2 | 0 | 7 | 5.94767 | 1 |
| 1 | 3 | 4 | 7 | 2.40523 | 1 |
| 1 | 4 | 8 | 6 | $-$1.85508 | 2 |
| 1 | 5 | 2 | 5 | 2.74069 | 1 |
| 1 | 6 | 2 | 4 | 2.02281 | 1 |
| 2 | 1 | 10 | 8 | $-$2.19054 | 2 |
| 2 | 2 | 7 | 7 | $-$0.25159 | 2 |
| 2 | 3 | 9 | 5 | $-$3.45857 | 2 |
| 2 | 4 | 5 | 3 | $-$1.35190 | 2 |
| 2 | 5 | 9 | 2 | $-$5.61221 | 2 |
| 2 | 6 | 5 | 2 | $-$2.06978 | 2 |
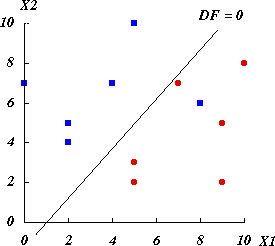 図 1.判別図 |
|---|
> DF <- as.matrix(data) %*% a + c > DF [,1] [1,] 3.6732640 [2,] 5.9476686 [3,] 2.4052331 [4,] -1.8550822 [5,] 2.7406910 [6,] 2.0228111 [7,] -2.1905401 [8,] -0.2515934 [9,] -3.4585709 [10,] -1.3518953 [11,] -5.6122107 [12,] -2.0697752 > predicted <- (DF < 0)+1 > predicted [,1] [1,] 1 [2,] 1 [3,] 1 [4,] 2 [5,] 1 [6,] 1 [7,] 2 [8,] 2 [9,] 2 [10,] 2 [11,] 2 [12,] 2 > plot(X2 ~ X1, data=data, col=c("blue", "red")[group], pch=c(15, 19)[group]) > abline(-c/a[2], -a[1]/a[2]) > text(9, 9, "DF=0")