重回帰分析(ステップワイズ変数選択) Last modified: Sep 21, 2008
目的
ステップワイズ変数選択による重回帰分析を行う
使用法
sreg(data, stepwise=TRUE, P.in=0.05, P.out=0.05, predict=FALSE, verbose=TRUE)
引数
data データ行列。従属変数は最終列におき,それ以外は独立変数と見なす。
stepwise ステップワイズ変数選択をする
P.in Pin(デフォルトは 0.05)
P.out Pout(デフォルトは 0.05,Pout ≧ Pin のこと)
predict 個々の予測結果などを出力するかどうか(デフォルトは FALSE)
verbose ステップワイズ変数選択の途中結果を出力する
偏回帰係数など,分割表,決定係数など,予測値などに関する結果はそれぞれ,「分析結果」,「分散分析表」,「決定係数」,「予測」の要素名で参照できる。
plot メソッドとして,3種類の回帰診断プロットを用意している(このページの下の方を参照)。
ソース
インストールは,以下の 1 行をコピーし,R コンソールにペーストする
source("http://aoki2.si.gunma-u.ac.jp/R/src/sreg.R", encoding="euc-jp")
sreg <- function( data, # 最終列が従属変数
stepwise=TRUE, # ステップワイズ変数選択をする
P.in=0.05, # Pin
P.out=0.05, # Pout (Pout ≧ Pin のこと)
predict=FALSE, # 各ケースの予測値を出力する
verbose=TRUE) # ステップワイズ変数選択の途中結果を出力する
{
sd2 <- function (x, na.rm=FALSE)
{
if (is.matrix(x)) {
apply(x, 2, sd, na.rm=na.rm)
}
else if (is.data.frame(x)) {
sapply(x, sd, na.rm=na.rm)
}
}
stat <- function() # 基本統計量の出力
{
tbl <- data.frame(平均値=mean, 不偏分散 =var, 標準偏差=sd)
print(tbl, digits=5)
if (any(var == 0)) {
stop("分散が0になる変数があります")
}
cat("\n***** 相関係数行列 *****\n")
print(r, digits=5)
}
step.out <- function(isw) # 変数選択の途中結果を出力
{
step <<- step+1 # ステップ数
syy <- ss[q1] # 従属変数の平方和
names(syy) <- NULL # 後々余計な名前が付くのを防ぐ
lxi <- lx[1:ni] # モデルに含まれている変数の列番号
b1 <- r[q1, lxi] # 標準化偏回帰係数
b <- b1*sd[q1]/sd[lxi] # 偏回帰係数
b0 <- mean[q1]-sum(b*mean[lxi]) # 定数項
sr <- sum(b*ss[lxi]) # 回帰の平方和
se <- syy-sr # 残差の平方和
if (se < 0 && abs(se/syy) < 1e-12) { # 負の値になっても誤差範囲なら許容
se <- 0
}
idf1 <- ni # 回帰の平方和の自由度
idf2 <- nc-ni-1 # 誤差の平方和の自由度
vr <- sr/idf1 # 回帰の平均平方
ve <- se/idf2 # 残差の平均平方
if (ve == 0) { # 完全に当てはまる場合
f <- fp9 <- NA
stde <- tv <- pp <- rep(NA, ni)
seb0 <- tv0 <- pp0 <- NA
warning("従属変数の予測値と観測値が完全に一致します。分析の指定に間違いはないですか?")
}
else { # 普通はこちら
f <- vr/ve # 分散分析の F 値
fp9 <- pf(f, idf1, idf2, lower.tail=FALSE) # 対応する P 値
}
rhoy <- se/syy # 残差平方和の割合
if (ve != 0) {
seb <- r[cbind(lxi, lxi)]*rhoy/idf2*var[q1]/var[lxi]
stde <- sqrt(seb) # 偏回帰係数の標準誤差
tv <- abs(b/stde) # t 値
pp <- pt(tv, idf2, lower.tail=FALSE)*2 # P 値
temp <- mean[lxi]/sd[lxi]
seb0 <- sqrt((1/nc+temp %*% r[lxi, lxi, drop=FALSE] %*% temp/(nc-1))*ve)
tv0 <- abs(b0/seb0)
pp0 <- pt(tv0, idf2, lower.tail=FALSE)*2
}
stde[ni+1] <- seb0
tv[ni+1] <- tv0
pp[ni+1] <- pp0
adj.r2 <- 1-ve/syy*(nc-1) # 自由度調整済み決定係数
if (rhoy != 0 && isw != 0) {
r2.change <- old.rhoy-rhoy # 決定係数の増分
f.change <- r2.change*idf2/rhoy # F 値に換算
p.change <- if (f.change < 0) NA # P 値
else pf(f.change, 1, idf2, lower.tail=FALSE)
}
else {
p.change <- NA
}
if (isw != 0 && verbose) { # ステップのまとめ
cat(sprintf("\n***** ステップ %i ***** ", step))
cat(sprintf("%s変数: %s\n", c("編入", "除去")[isw], vname[ip]))
}
multico <- r[cbind(lxi, lxi)] # 分散拡大要因
result1 <- data.frame( 偏回帰係数=c(b, b0), # 結果をデータフレームにする
標準誤差=stde,
"t値"=tv,
"P値"=format.pval(pp, 3, 1e-3),
標準化偏回帰係数=c(b1, NA),
トレランス=c(1/multico, NA),
分散拡大要因=c(multico, NA))
rownames(result1) <- c(vname[lxi], "定数項") # 行名を付ける
class(result1) <- c("sreg", "data.frame") # print.sreg を使うための設定
if (verbose) print(result1) # 結果出力
result3 <- data.frame( 平方和=c(sr, se, syy), # 分散分析表のデータフレーム
自由度=c(ni, idf2, nc-1),
平均平方=c(vr, ve, NA),
"F値"=c(f, NA, NA),
"P値"=c(format.pval(fp9, 3, 1e-3), NA, NA))
rownames(result3) <- c("回帰", "残差", "全体") # 行名を付ける
class(result3) <- c("sreg", "data.frame") # print.sreg を使うための設定
if (verbose) print(result3) # 結果出力
loglik <- 0.5*(sum(-nc*(log(2*pi)+1-log(nc)+log(se))))
AIC <- 2*ni+4-2*loglik
result4 <- c(重相関係数=sqrt(1-rhoy),
"決定係数(重相関係数の二乗)"=1-rhoy)
if (adj.r2 > 0) {
result4 <- c(result4, 自由度調整済み重相関係数の二乗=adj.r2)
}
result4 <- c(result4, 対数尤度=loglik, AIC=AIC)
class(result4) <- c("sreg", "numeric") # print.sreg を使うための設定
if (verbose) print(result4) # 結果出力
if (stepwise && !is.na(p.change)) {
result5 <- c( 決定係数の増分=r2.change,
"増分に対するF値"=f.change,
"第1自由度"=1,
"第2自由度"=idf2,
"増分に対するP値"=p.change)
class(result5) <- c("sreg", "numeric") # print.sreg を使うための設定
if (verbose) print(result5) # 結果出力
}
else {
result5 <- NA
}
old.rhoy <<- rhoy
return(list( b=b, b0=b0, ve=ve, coefficients=result1,
anova.table=result3, Rs=result4, delta=result5))
}
fmax <- function() # モデルに取り入れる変数の探索
{
kouho <- 1:q
if (ni > 0) {
kouho <- (1:q)[-lx[1:ni]]
}
kouho2 <- cbind(kouho, kouho)
temp <- 1/(r[kouho2]*r[q1, q1]/(r[q1, kouho]^2)-1)
ip <- which.max(temp)
return(c(temp[ip], kouho[ip]))
}
fmin <- function() # モデルから捨てる変数の探索
{
kouho <- lx[1:ni]
kouho2 <- cbind(kouho, kouho)
temp <- r[q1, kouho]^2/(r[kouho2]*r[q1, q1])
ip <- which.min(temp)
return(c(temp[ip], lx[ip]))
}
sweep.sreg <- function(r) # 掃き出し法
{
ap <- r[ip, ip]
if (abs(ap) <= EPSINV) {
stop("正規方程式の係数行列が特異行列です")
}
for (i in 1:q1) {
if (i != ip) {
temp <- r[ip, i]/ap
for (j in 1:q1) {
if (j != ip) {
r[j, i] <- r[j, i]-r[j, ip]*temp
}
}
}
}
r[,ip] <- r[,ip]/ap
r[ip,] <- -r[ip,]/ap
r[ip, ip] <- 1/ap
return(r)
}
proc.predict <- function() # 予測値,標準化残差を求める
{
lxi <- lx[1:ni]
ve <- ans.step.out$ve # 残差の平均平方
constant <- ans.step.out$b0 # 定数項
b <- ans.step.out$b # 偏回帰係数
y <- data[,ncol(data)] # 観察値(従属変数)
data <- as.matrix(data)[, lxi, drop=FALSE] # モデル中の独立変数を順序通りに取り出す
est <- data%*%b+constant # 予測値
res <- y-est # 残差
r <- r[lxi, lxi]
data <- scale(data)*sqrt(nc/(nc-1)) # データの標準化
stres <- apply(data, 1, function(arg) arg%*%r%*%arg)
stres <- res/sqrt(ve*(1-(stres+1)/nc)) # 標準化残差
result <- data.frame(観察値=y, 予測値=est, 残差=res, 標準化残差=stres)
return(result)
}
############## 関数本体
EPSINV <- 1e-6 # 特異行列の判定値
MULTICO <- 10 # 分散拡大要因の基準値
if (P.out < P.in) { # Pout ≧ Pin でなければならない
P.out <- P.in
}
step <- 0 # step.out にて,大域代入される
old.rhoy <- 1 # step.out にて,大域代入される
vname <- colnames(data) # 変数名(なければ作る)
if (is.null(vname)) {
vname <- colnames(data) <- c(paste("x", 1:(ncol(data)-1), sep=""), "y")
}
data <- subset(data, complete.cases(data)) # 欠損値を含むデータを除く
nc <- nrow(data) # ケース数
q1 <- ncol(data) # 従属変数の位置
if (verbose) {
cat(sprintf("有効ケース数: %i\n", nc))
cat(sprintf("従属変数: %s\n", vname[q1]))
}
q <- q1-1 # 独立変数の個数
if (stepwise == FALSE && nc <= q1) {
stop("独立変数の個数よりデータ数が多くなければなりません")
}
if (q == 1) { # 単回帰
stepwise <- FALSE
}
mean <- colMeans(data) # 平均値
sd <- sd2(data) # 標準偏差
var <- sd^2 # 分散
ss <- (var(data)*(nc-1))[,q1] # 共変動ベクトル
r <- cor(data) # 相関係数行列
if (verbose) stat() # 基礎統計量の出力
stde <- tv <- pp <- numeric(q1) # メモリ確保
if (stepwise == FALSE) { # 変数選択をしないとき
for (ip in 1:q) {
r <- sweep.sreg(r)
}
lx <- 1:q # モデルに含まれる独立変数の列番号を保持
ni <- q # モデルに含まれる独立変数の個数
ans.step.out <- step.out(0)
}
else { # 変数選択をするとき
if (verbose) {
cat(sprintf("\n変数編入基準 Pin: %.5g\n", P.in))
cat(sprintf("変数除去基準 Pout: %.5g\n", P.out))
}
lx <- numeric(q) # モデルに含まれる独立変数の列番号を保持
ni <- 0 # モデルに含まれる独立変数の個数
while (ni < min(q, nc-2)) {
ans.max <- fmax() # 編入候補変数を探索
P <- (nc-ni-2)*ans.max[1] # F 値から
P <- pf(P, 1, nc-ni-2, lower.tail=FALSE) # P 値を求める
ip <- ans.max[2] # 変数の位置
if (verbose) cat(sprintf("編入候補変数: %-15s P : %s",vname[ip], format.pval(P, 3, 1e-3)))
if (P > P.in) {
if (verbose) cat(" ***** 編入されませんでした\n")
break
}
if (verbose) cat(" ***** 編入されました\n")
ni <- ni+1
lx[ni] <- ip
r <- sweep.sreg(r)
ans.step.out <- step.out(1) # 途中結果を出力する
repeat { # 変数除去のループ
ans.min <- fmin() # 除去候補変数について同じく
P <- (nc-ni-1)*ans.min[1]
P <- pf(P, 1, nc-ni-1, lower.tail=FALSE)
ip <- ans.min[2]
if (verbose) cat(sprintf("除去候補変数: %-15s P : %s",vname[ip], format.pval(P, 3, 1e-3)))
if (P <= P.out) {
if (verbose) cat(" ***** 除去されませんでした\n")
break # 変数除去の終了
}
else {
if (verbose) cat(" ***** 除去されました\n")
lx <- lx[-which(lx == ip)]
ni <- ni-1
r <- sweep.sreg(r)
ans.step.out <- step.out(2) # 途中結果を出力する
}
}
}
}
if (ni == 0) {
warning(paste("条件( Pin <", P.in, ")を満たす独立変数がありません"))
}
else {
result6 <- proc.predict() # 予測
ans <- list( 分析結果=ans.step.out$coefficients,
分散分析表=ans.step.out$anova.table,
決定係数=ans.step.out$Rs,
予測=result6)
if (stepwise) {
if (verbose) cat("\n===================== 結果 =====================\n")
print(ans$分析結果)
print(ans$分散分析表)
print(ans$決定係数)
if (predict) {
cat("\n")
print(ans$予測, digits=5)
}
}
class(ans) <- c("sreg", "list") # plot.sdis を使うための設定
invisible(ans)
}
}
print.sreg <- function(result) # sreg クラスのオブジェクトの print メソッド
{
if (class(result)[2] == "list") {
print.default(result)
}
else if (class(result)[2] == "data.frame") {
result <- capture.output(print.data.frame(result, digits=5))
result <- gsub("$", "\\\n", result)
result <- gsub("<NA>", " ", result)
result <- gsub("NA", " ", result)
cat("\n", result, sep="")
}
else if (length(result) == 5) {
nm <- names(result)
if (nm[1] == "重相関係数") {
cat(sprintf( "\n%s\t%.5f\n%s\t%.5f\n%s\t%.5f\n%s\t%.5f\n%s \t%.5f\n",
nm[1], result[1], nm[2], result[2], nm[3], result[3],
nm[4], result[4], nm[5], result[5]))
}
else {
cat(sprintf( "\n%s\t%.5f\n%s\t%.5f\n%s\t%i\n%s\t%i\n%s\t%.5f\n\n",
nm[1], result[1], nm[2], result[2], nm[3], result[3],
nm[4], result[4], nm[5], result[5]))
}
}
}
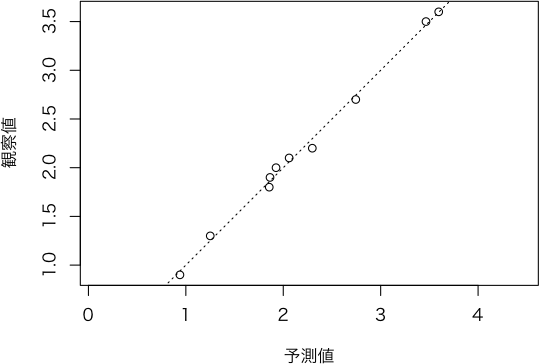
plot.sreg <- function(result, which=c("stdres", "qqplot", "slope1"), ...) # sdis クラスのオブジェクトの plot メソッド
{
which <- match.arg(which)
if (which == "stdres") { # 予測値--標準化残差
plot(result$予測$標準化残差 ~ result$予測$予測値, xlab="予測値", ylab="標準化残差", ...)
}
else if (which == "qqplot") { # 標準化残差の Q-Q プロット
n <- length(result$予測$標準化残差)
qqnorm(result$予測$標準化残差, xlab="理論値", ylab="標準化残差", ...)
qqline(result$予測$標準化残差, lty=3)
}
else { # 予測値--観察値
plot(result$予測$観察値 ~ result$予測$予測値, xlab="予測値", ylab="観察値", asp=1, ...)
abline(0, 1, lty=3)
}
}
使用例
> dat <- matrix(c( # 3 列目が従属変数
1.2, 1.9, 0.9,
1.6, 2.7, 1.3,
3.5, 3.7, 2.0,
4.0, 3.1, 1.8,
5.6, 3.5, 2.2,
5.7, 7.5, 3.5,
6.7, 1.2, 1.9,
7.5, 3.7, 2.7,
8.5, 0.6, 2.1,
9.7, 5.1, 3.6
), byrow=TRUE, nc=3)
> ans <- sreg(dat)
有効ケース数: 10
従属変数: y
平均値 不偏分散 標準偏差
x1 5.4 7.99778 2.82803
x2 3.3 3.92222 1.98046
y 2.2 0.74444 0.86281
***** 相関係数行列 *****
x1 x2 y
x1 1.00000 0.12816 0.75499
x2 0.12816 1.00000 0.74388
y 0.75499 0.74388 1.00000
変数編入基準 Pin: 0.05
変数除去基準 Pout: 0.05
編入候補変数: x1 P : 0.0116 ***** 編入されました
***** ステップ 1 ***** 編入変数: x1
偏回帰係数 標準誤差 t値 P値 標準化偏回帰係数 トレランス 分散拡大要因
x1 0.23034 0.070732 3.2565 0.0116 0.75499 1 1
定数項 0.95615 0.426497 2.2419 0.0553
平方和 自由度 平均平方 F値 P値
回帰 3.8191 1 3.81907 10.605 0.0116
残差 2.8809 8 0.36012
全体 6.7000 9
重相関係数 0.75499
決定係数(重相関係数の二乗) 0.57001
自由度調整済み重相関係数の二乗 0.51626
決定係数の増分 0.57001
増分に対するF値 10.60508
第1自由度 1
第2自由度 8
増分に対するP値 0.01159
除去候補変数: x1 P : 0.0116 ***** 除去されませんでした
編入候補変数: x2 P : <0.001 ***** 編入されました
***** ステップ 2 ***** 編入変数: x2
偏回帰係数 標準誤差 t値 P値 標準化偏回帰係数 トレランス 分散拡大要因
x1 0.20462 0.0075643 27.0506 <0.001 0.67067 0.98358 1.0167
x2 0.28663 0.0108015 26.5365 <0.001 0.65793 0.98358 1.0167
定数項 0.14918 0.0545063 2.7368 0.0290
平方和 自由度 平均平方 F値 P値
回帰 6.671644 2 3.3358218 823.48 <0.001
残差 0.028356 7 0.0040509
全体 6.700000 9
重相関係数 0.99788
決定係数(重相関係数の二乗) 0.99577
自由度調整済み重相関係数の二乗 0.99456
決定係数の増分 0.42576
増分に対するF値 704.18341
第1自由度 1
第2自由度 7
増分に対するP値 0.00000
除去候補変数: x2 P : <0.001 ***** 除去されませんでした
===================== 結果 =====================
偏回帰係数 標準誤差 t値 P値 標準化偏回帰係数 トレランス 分散拡大要因
x1 0.20462 0.0075643 27.0506 <0.001 0.67067 0.98358 1.0167
x2 0.28663 0.0108015 26.5365 <0.001 0.65793 0.98358 1.0167
定数項 0.14918 0.0545063 2.7368 0.0290
平方和 自由度 平均平方 F値 P値
回帰 6.671644 2 3.3358218 823.48 <0.001
残差 0.028356 7 0.0040509
全体 6.700000 9
重相関係数 0.99788
決定係数(重相関係数の二乗) 0.99577
自由度調整済み重相関係数の二乗 0.99456
対数尤度 15.13807
AIC -22.27614
> ans$予測 # 予測値などの要素名は「予測」
観察値 予測値 残差 標準化残差
1 0.9 0.9393205 -0.039320470 -0.78158652
2 1.3 1.2504744 0.049525617 0.93174116
3 2.0 1.9258808 0.074119153 1.27026078
4 1.8 1.8562092 -0.056209168 -0.94541178
5 2.2 2.2982502 -0.098250198 -1.62854986
6 3.5 3.4652471 0.034752908 0.86640471
7 1.9 1.8640714 0.035928614 0.65844698
8 2.7 2.7443496 -0.044349627 -0.76144091
9 2.1 2.0604021 0.039597939 0.87031205
10 3.6 3.5957948 0.004205233 0.08634549
plot メソッドでは,以下の3種類の図を描くことができる
> plot(ans)
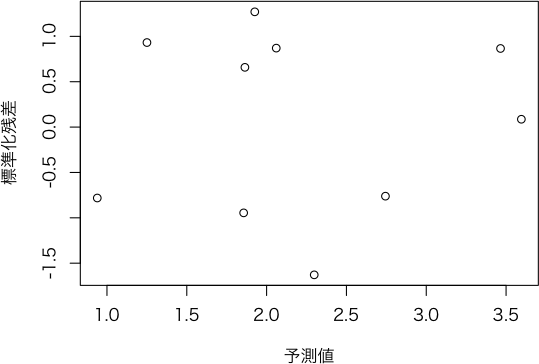 > plot(ans, which="qqplot", main="")
> plot(ans, which="qqplot", main="")
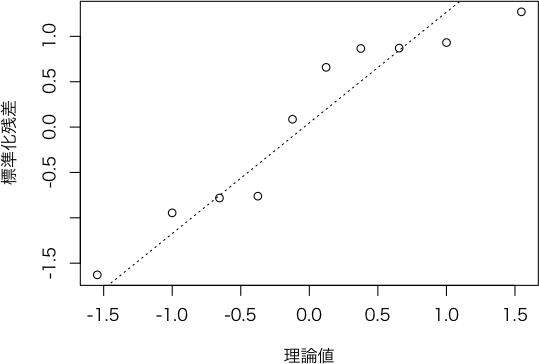 > plot(ans, which="slope1")
> plot(ans, which="slope1")
 解説ページ
解説ページ
直前のページへ戻る E-mail to Shigenobu AOKI
