No.22920 Re: 【R】表の突合せ、charactermatch()関数の使い方 【青木繁伸】 2020/06/14(Sun) 14:34
現時点での(効率がよいかどうかはともかく)プログラムはどのようになっていますか。
No.22921 Re: 【R】表の突合せ、charactermatch()関数の使い方 【明石】 2020/06/14(Sun) 15:34
青木先生 様;
お忙しいところを失礼いたします,明石と申します
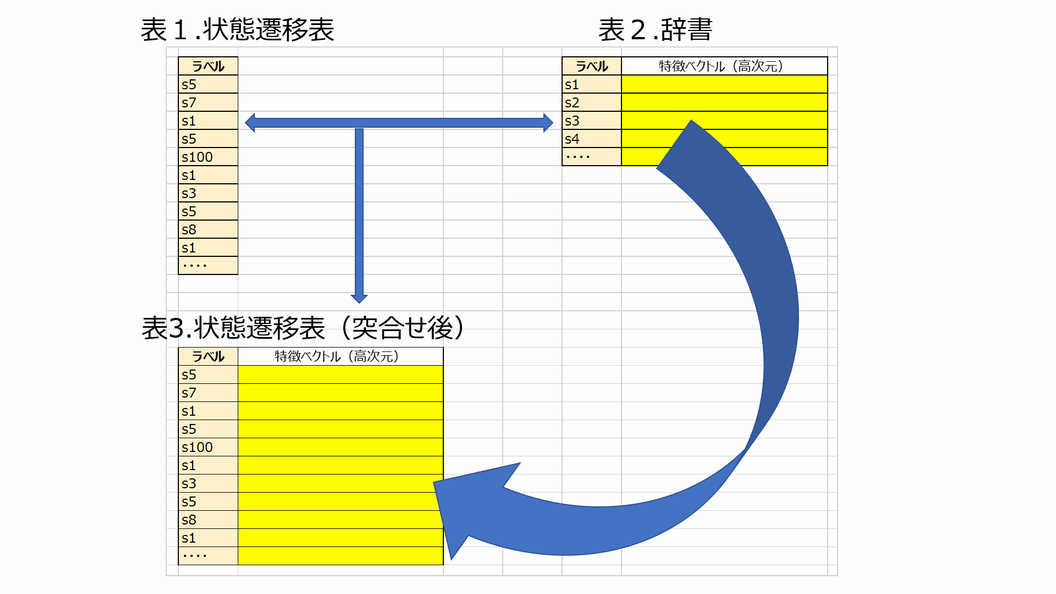
以下,私が作成しましたRプログラムをお示しします。# 表1の読み込み以上,どうぞよろしくお願いいたします。
# 実際のデータは,以下のように,半角スペース区切りの文字列ベクトル
# s5 s7 s1 s5 s100 s1 s3 s5 s8 s1 ,,,,,,,
# ファイル名は,"BOW_input.txt"
BOW <- scan("BOW_input.txt", what = character(), sep = "\n", blank.lines.skip = F) ######
bow <- strsplit(BOW, " ")
bow <- unlist(bow)
# 表2の読み込み
# ファイル名は,Vectors_matrix
vec <- read.table("Vectors_matrix.csv", header=T , sep=",", na.strings=c("NA",""," "),stringsAsFactors=F, row=1)
vec <- as.matrix(vec)
label <- rownames(vec)
# 表3の(空)行列を作成する
nr <- length(bow)
nc <- ncol(vec)
mx <- matrix(0, nr=nr, nc=nc)
rownames(mx) <- bow
colnames(mx) <- colnames(vec)
# charmatch()関数で,インデックスを得る
jun <- charmatch(bow, label)
# ここが,ご教示願いたい箇所です。
# charamatch()関数で得られたインデックスは,このように利用しましたが,
# もっと良い書き方があるように思えてなりません。
for (i in seq_along(bow)) {
mx[i,] <- vec[jun[i],]
}
# 所望する,表3
mx <- as.data.frame(mx)
No.22922 Re: 【R】表の突合せ、charactermatch()関数の使い方 【青木繁伸】 2020/06/14(Sun) 16:13
jun を求めた後,以下のようにするmx2 <- vec[jun,] # 空の行列を作る必要はないas.data.frame で重複する行名は s5.1 などになる。それが不都合な場合は,ラベルを新たな列として作るとよいでしょう。
rownames(mx2) <- bow # あとで as.data.frame すると,重複名は修正される
colnames(mx2) <- colnames(vec)
mx2 <- data.frame(mx2, check.rows=FALSE)
# check
all(mx == mx2)
mx2 <- vec[jun,] が何をしているのか不思議かもしれませんが,> ans <- c(1,2,1,1,2,2,1,2,1,1)と同じようなことをしているのです。
> x <- c("No", "Yes")
> x[ans]
[1] "No" "Yes" "No" "No" "Yes" "Yes" "No" "Yes"
[9] "No" "No"
No.22923 Re: 【R】表の突合せ、charactermatch()関数の使い方 【明石】 2020/06/14(Sun) 19:26
青木先生 様;
お忙しいところを失礼いたします,明石と申します。
ありがたいご教示をいただき,誠にありがとうございました。
御礼を申し上げます。
誠に恥ずかしいのですが,
にわかには理解できませんので,追試しながら,技を学びたいと思います。
青木先生にプログラムを見ていただく幸運に恵まれました。
ありがとうございました。
ありがとうございました。
//
No.22924 Re: 【R】表の突合せ、charactermatch()関数の使い方 【明石】 2020/06/14(Sun) 19:35
青木先生 様;
お忙しいところを失礼いたします,明石と申します
私がまさに知りたかったのは,この1行です。
これが知りたかったのです。
求めたインデックスjunを利用して,1行で書ける方法が知りたかったのです。
> mx2 <- vec[jun,] が何をしているのか不思議かもしれませんが,
> ans <- c(1,2,1,1,2,2,1,2,1,1)
> x <- c("No", "Yes")
> x[ans]
> [1] "No" "Yes" "No" "No" "Yes" "Yes" "No" "Yes"
> [9] "No" "No"
知りたかったことを,ご教示いただき,
勇気を振り絞って,投稿させていただき,よかったなと思います。
ありがとうございました。
ありがとうございました。
//
● 「統計学関連なんでもあり」の過去ログ--- 048 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る