No.22841 複数のヒストグラムの取り扱いについて 【平沢】 2019/09/20(Fri) 16:35
青木先生
初めての投稿になります。
大学の研究で行き詰ってしまったためご教授お願い致します。
試験体に含まれた薬剤量と,その薬剤の主成分が試験体のどこにどれほど入っているかを分析しています。データとしては,1つの試験体をおおよそ25000分割し(試験体毎に分割数は異なる),その1点1点で主成分濃度を得ています。
例えば,試験体Aでは薬剤量149kg/m3,主成分濃度のサンプル数26510個といったものです。
以上のようなデータが30試験体分あり,それぞれで主成分濃度のヒストグラムを作成致しました。ヒストグラムの階級数はスタージェスの公式を用いて算出しています。
ヒストグラムの形について,主観では,薬剤量が 1)一定値以下 2)一定値付近 3)一定値以上の3タイプに分類されるように見えておりますが,これを客観的に言える方法が無く困っております。
2)一定値付近では比較的正規分布しているように見えたためコルモゴロフ=スミルノフ検定を行いましたが,帰無仮説は棄却されました。
稚拙な説明で申し訳ございませんが,ご助言いただければ幸いです。
No.22843 Re: 複数のヒストグラムの取り扱いについて 【青木繁伸】 2019/09/20(Fri) 23:06
データのイメージがはっきりつかめないので,シミュレーションデータを作って分析してみました。
n
試験体(貴方の例では n = 30) のそれぞれについてかなりのデータがあり,それを class (貴方の例では class = 25000)
区間に分割してヒストグラム(度数分布)を作った。このヒストグラムについて,似ているもののグループ分けをしたい?set.seed(123)
# class = 2500
class = 250 # ヒストグラムの階級数
N = 10000 # データ数
# n = 30
n = 15 # 試験体
data0 = matrix(0, n, N) # 大元のデータ(試験体数 x データ数)
data = matrix(0, n, class) # 試験体ごとの度数分布
Mean = runif(n, -1, 1) # 試験体ごとの平均値(取りあえず)
for (i in 1:n) { # 試験体ごとの元データ(取りあえず正規分布に従うとして)
data0[i, ] = rnorm(N, mean=Mean[i])
}
Min = min(data0) # データ全体の最小値(度数分布を作るために)
Max = max(data0) # データ全体の最大値(度数分布を作るために)
for (i in 1:n) { # 試験体ごとの度数分布(ヒストグラムは描かない)
data[i, ] = hist(data0[i,], breaks=seq(Min, Max, length=class+1), plot=FALSE)$counts
}
さて,このような,試験体 x 度数分布の集計結果をデータとみなして主成分分析を行うとどうなるか?a = prcomp(data) # scale.=TRUE が必要かどうか?
主成分分析の結果を図示する。試験体の配置をみるために,主成分得点を図示する。
図をクリックすると拡大表示
次の発言に続く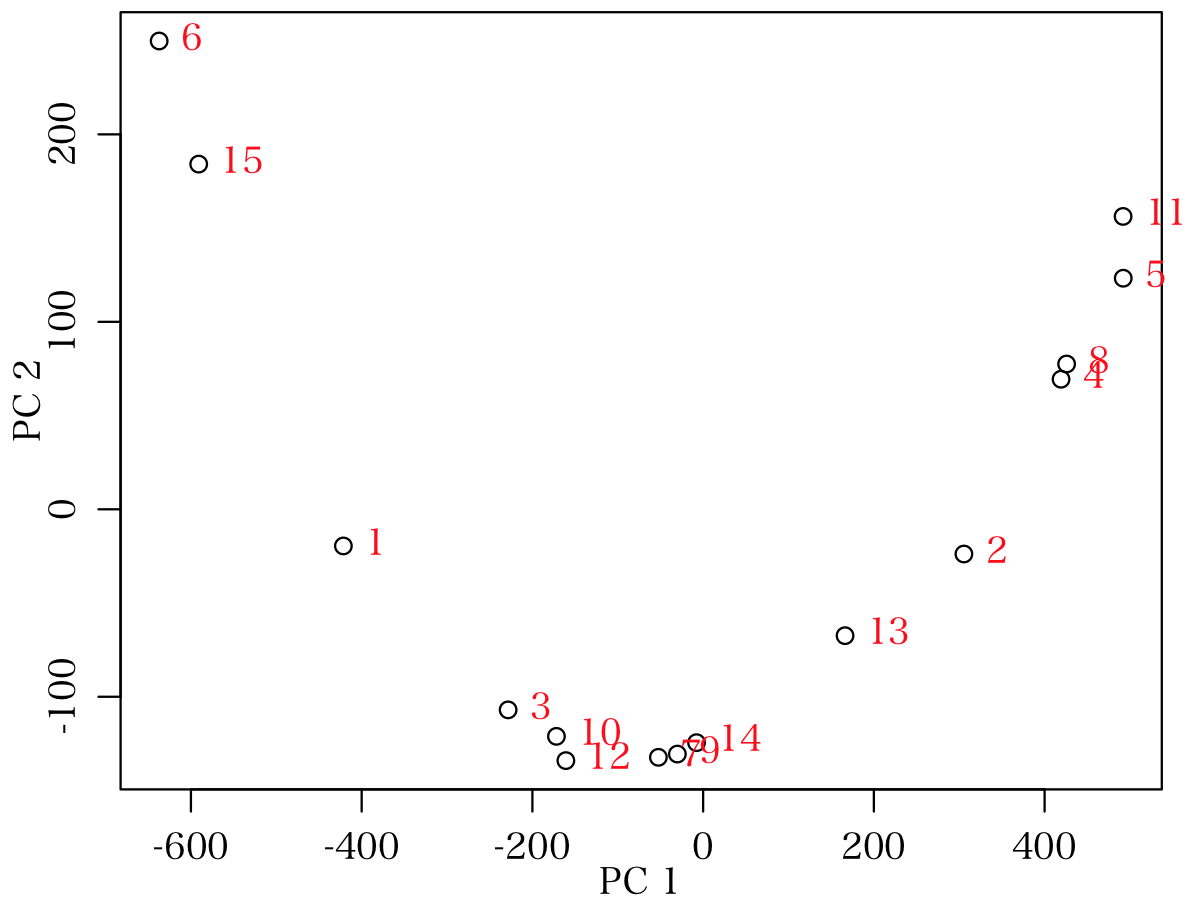
No.22844 Re: 複数のヒストグラムの取り扱いについて 【青木繁伸】 2019/09/20(Fri) 23:09
続き
第1主成分の順番で度数分布を図示してみる。plot(c(Min, Max), c(1, n), type="n", xlab="class", ylab="sample no.", yaxt="n")
t = order(a$x[,1])
for (i in 1:30) {
points(seq(Min, Max, length=class+1), rep(i, class+1), pch = 19, cex=sqrt(data[t[i],] )/10)
text(-4, i, t[i], col="red")
}
先の図からも似ているもの同士の位置関係がわかるが,実際どのように似ているかを試験体ごとの度数分布を示してみる。
第一主成分の順番で表示してみると,平均値の大きさにしたがって配置されていることがわかる。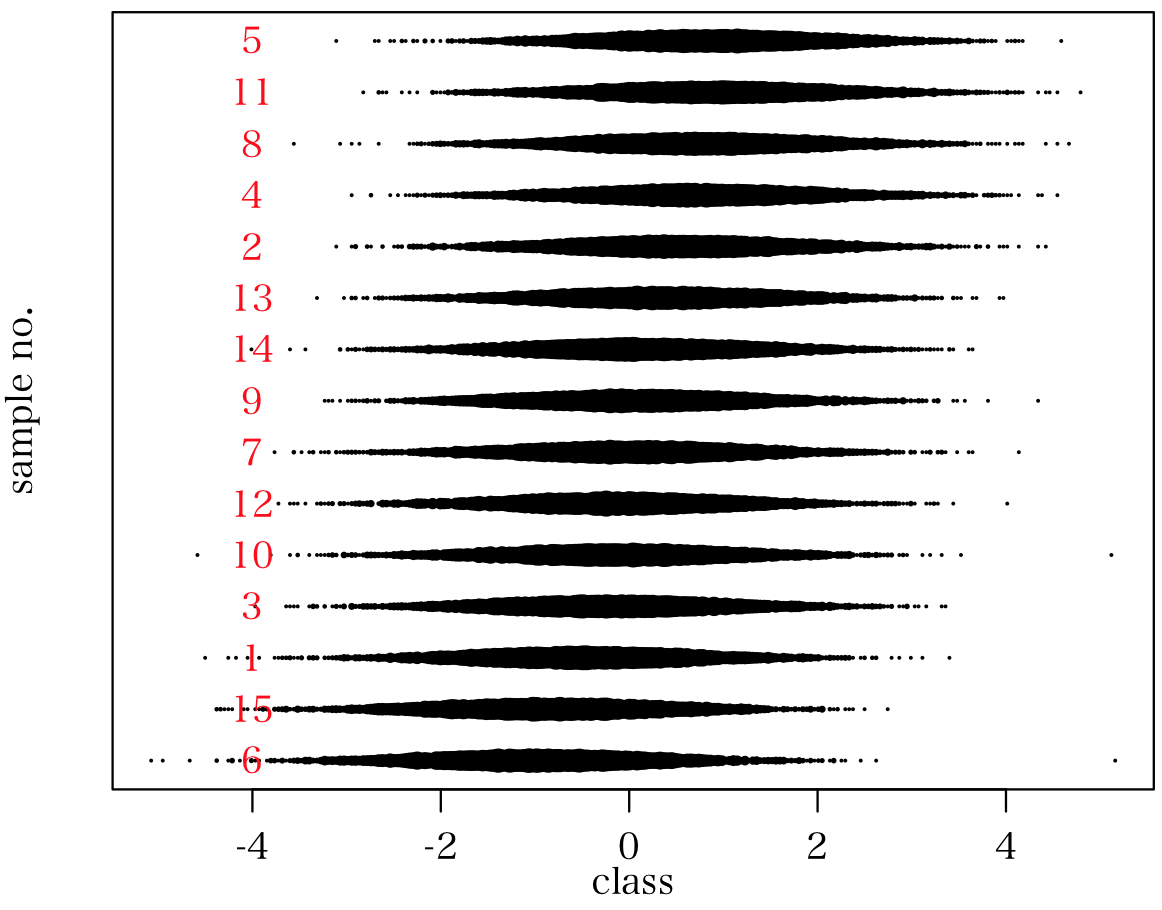
No.22846 Re: 複数のヒストグラムの取り扱いについて 【青木繁伸】 2019/09/20(Fri) 23:15
第2主成分の順でプロットしてみる。plot(c(Min, Max), c(1, n), type="n", xlab="class", ylab="sample no.", yaxt="n")
t = order(a$x[,2]) # 第2主成分を指定する
for (i in 1:30) {
points(seq(Min, Max, length=class+1), rep(i, class+1), pch = 19, cex=sqrt(data[t[i],] )/10)
text(-4, i, t[i], col="red")
}
右上,左上,下部の3パターンに分類できる。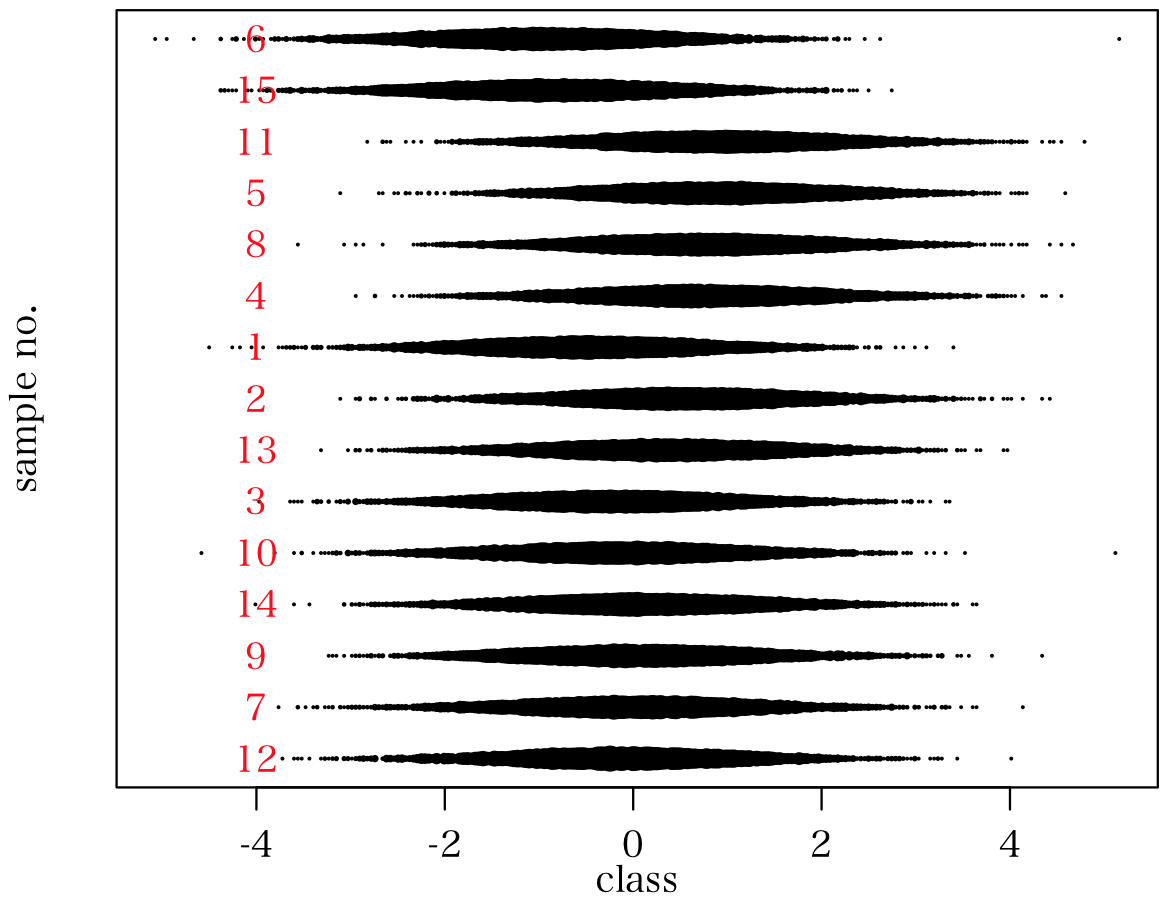
No.22847 Re: 複数のヒストグラムの取り扱いについて 【青木繁伸】 2019/09/20(Fri) 23:21
結局の所,試験体ごとの度数分布をデータと見なして似たもの同士を集める統計手法を使えばどうだろうかということ。
因子分析,対応分析,クラスター分析でもよいだろうと思う。(私が理解したデータ構造があたっていれば)
No.22848 Re: 複数のヒストグラムの取り扱いについて 【平沢】 2019/09/22(Sun) 14:06
青木先生
ご返信ありがとうございます。
まだRを初めて間もないため理解に時間がかかり
返信が遅くなりました,申し訳ございません。
データ構造につきましては大丈夫です。
スケールはnが試験体名,classは薬剤濃度 kg/m^3のため
TRUEで良いかと思います。
まずは主成分分析をしてみる,というアドバイスありがとうございます。
素人には中々頭がそこまで回らず,先生にお聞きして本当に良かったです…。
実際のデータで試してみたいと思います。
またそこで何かありましたら頼りにさせていただければ幸いです。
ご多用のところ,ありがとうございました。
No.22849 Re: 複数のヒストグラムの取り扱いについて 【平沢】 2019/09/24(Tue) 15:54
青木先生
度々失礼致します。
不明な点が2点ありましたのでお聞きしたく存じます。
>data0 = matrix(0, n, N) # 大元のデータ(試験体数 x データ数)
N数が試験体ごとに異なるのですが,
この場合どういう風に行列の指定をしたらよろしいでしょうか。
最もデータ数の多いものに合わせれば問題ないでしょうか。
>Mean = runif(n, -1, 1) # 試験体ごとの平均値(取りあえず)
なぜこの値が試験体毎の平均値であるのか,わかりませんでした。
以上,2点お願い致します。
No.22850 Re: 複数のヒストグラムの取り扱いについて 【青木繁伸】 2019/09/25(Wed) 16:35
挙げたのは例に過ぎないので,実際の貴方のデータを使えば良いのです。
> N数が試験体ごとに異なるのですが,
> この場合どういう風に行列の指定をしたらよろしいでしょうか。
最終的な度数分布データを作るための架空データなので,貴方の場合は試験体ごとの実際のデータから度数分布データを求めればよいだけです。
> なぜこの値が試験体毎の平均値であるのか,わかりませんでした。
これも,最終的な度数分布データを作るための架空データなので,貴方の場合は試験体ごとの平均値はそれこそ試験体の特徴を表す実際の値があるでしょう。
ようするに,貴方のやることは,試験体ごとの度数分布データをまとめるだけです。以下のような 30 × 25000 の行列データ 階級1 階級2 … 階級25000
試験体1 ○○ ○○ … ○○
試験体2 ○○ ○○ … ○○
:
試験体30 ○○ ○○ … ○○
No.22852 Re: 複数のヒストグラムの取り扱いについて 【平沢】 2019/09/25(Wed) 18:33
青木先生
ご返信ありがとうございます。
勘違いをしていました,納得できました。
失礼いたしました。
追加で質問したいのですが
複数のヒストグラムを1つにして比べたいとき,
適切な階級幅の設定方法で悩んでおります。
例えば,私が扱っているデータは
試験体A 最小値0,最大値7500,中央値2000,サンプル数27000
試験体B 最小値130,最大値10600,中央値2500,サンプル数25000
試験体C 最小値0,最大値7000,中央値1600,サンプル数26000
etc…
といったオーダーです。
1つずつ作る際はスタージェスの公式を参考にした階級数から
最大値と最小値の差を割ってでた数値をキリの良い階級幅に設定しています。
しかし,例えば試験体BとCでは以上の方法で算出した階級幅には
大きく差が出てしまいます。
できる限り偏りのないグラフにするために
何か方法があればお願い致します。
※私用のため3日間は返信ができないこと,ご容赦ください。
No.22853 Re: 複数のヒストグラムの取り扱いについて 【青木繁伸】 2019/09/25(Wed) 21:05
注意すべきは,全ての試験体で同じ階級設定をしないといけないこと。(当然ですが)
何回も書いているが,以下のようなデータ行列を用意すること 階級1 階級2 … 階級25000
試験体1 ○○ ○○ … ○○
試験体2 ○○ ○○ … ○○
:
試験体30 ○○ ○○ … ○○
>階級数は 25000 も必要ないとは思うが。
No.22854 Re: 複数のヒストグラムの取り扱いについて 【平沢】 2019/09/30(Mon) 12:55
青木先生
階級幅の平均をとるなどして調整してみます。
何度もご回答いただきありがとうございました。
● 「統計学関連なんでもあり」の過去ログ--- 048 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る