No.15412 Re: 分析方法について 【波音】 2011/10/01(Sat) 02:49
日が経っているので自己解決したかもしれませんが。。。
> この記述に関しては納得して理解できました。
ということと,改めて質問を考えてみるとやはり共分散分析をするということになるのではないでしょうか。文脈からもクラスタ分析を行う目的が応答変数をより良く説明するためのカテゴリカル型の説明変数を作成する,という目的があるように思えます。
つまりこういうこと↓
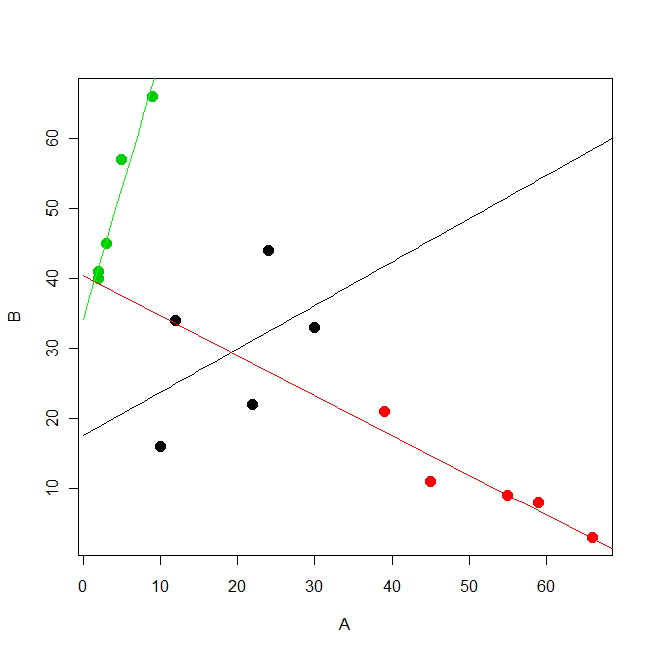
> cls <- c(1,1,1,1,1, 2,2,2,2,2, 3,3,3,3,3) # クラスタ変数
> A <- c(12,24,30,10,22, 45,55,66,59,39, 2,3,2,9,5) # 説明変数
> B <- c(34,44,33,16,22, 11,9,3,8,21, 40,45,41,66,57) # 応答変数
> result <- lm(B ~ A + cls + A:cls) # 共分散分析
> summary(result) # 係数表
Call:
lm(formula = B ~ A + cls + A:cls)
Residuals:
Min 1Q Median 3Q Max
-9.3051 -2.5403 -0.3103 1.9390 11.4407
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 17.5085 8.4890 2.062 0.0692 .
A 0.6271 0.4043 1.551 0.1553
cls2 22.9181 18.8851 1.214 0.2558
cls3 16.5777 10.2368 1.619 0.1398
A:cls2 -1.1958 0.5121 -2.335 0.0444 *
A:cls3 3.1143 1.2222 2.548 0.0313 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 6.804 on 9 degrees of freedom
Multiple R-squared: 0.9175, Adjusted R-squared: 0.8716
F-statistic: 20.01 on 5 and 9 DF, p-value: 0.0001243
> summary(aov(result)) # 分散分析表
Df Sum Sq Mean Sq F value Pr(>F)
A 1 3226.0 3226.0 69.6785 1.574e-05 ***
cls 2 657.4 328.7 7.0992 0.014110 *
A:cls 2 748.0 374.0 8.0776 0.009801 **
Residuals 9 416.7 46.3
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> xv <- seq(0, 70, 1) # 以下プロットのための記述
> yv.cls1 <- (17.50+0.00) + (0.62+0.00)*xv
> yv.cls2 <- (17.50+22.91) + (0.62+(-1.19))*xv
> yv.cls3 <- (17.50+16.57) + (0.62+3.11)*xv
> points(xv, yv.cls1, type="l", col="black")
> points(xv, yv.cls2, type="l", col="red")
> points(xv, yv.cls3, type="l", col="green")
詳しくはRのコードや共分散分析について調べて頂きたいのですが,共分散分析の意味するところは大きく2つあります。
・各群の平均値が有意に異なるか(分散分析)
・各群においてXの増分に対してYの増加,あるいは減少の度合い(傾き)は有意に異なるか(回帰分析)
今
回の例データでは3つのクラスタ間で応答変数Bの平均値が異なることが確認できます(そしてそれは統計的に有意な差が認められる=分散分析表でclsの項
は有意である)。また,各クラスタによって説明変数Aの増加に伴って,応答変数Bの増減(変化量)も変わります(分散分析表でAの項が有意である)。
結論としてまとめてみると:
・グリーンのクラスタは最もBの平均値が高く,Aが増加するとBも急激に増加する(他のクラスタの回帰係数:傾きが大きい)。
・ブラックのクラスタはグリーンよりも小さく,レッドより大きい。BはAの増加に伴って比較的なだらかに増加していく。
・レッドのクラスタは最もBの平均値が低く,Aが増加するとBは減少する(回帰係数の符号がマイナスである)。
みたいな知見が得られますが,例えば「公的自己意識が高く,私的自己意識の高い群は自己の劣勢認知度が高くなると劣等感が弱くなる」といったようなことが分かるのだと思います。