No.14736 Re: 指数分布の確率密度関数 【青木繁伸】 2011/06/07(Tue) 16:02
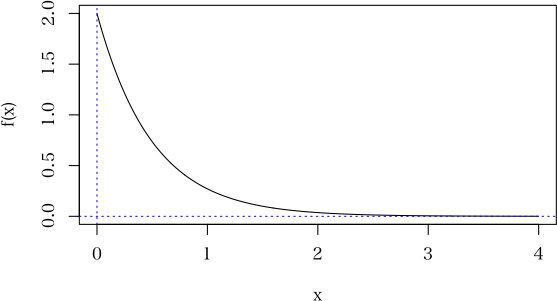
それは,確率ではなく,確率密度です。確率密度の上限値はありません(1 以上の値も取ります)。
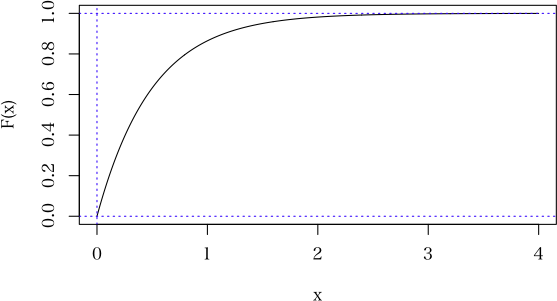
確率密度を積分したものが確率です。
R では,f(x) は dexp 関数で計算,確率は pexp 関数で計算。
0 〜 ∞ 区間での積分は,pexp(0, rate=2, lower.tail=FALSE) で,1 になります。
> x <- seq(0, 4, length=500)
> y <- dexp(x, rate=2)
> plot(x, y, type="l", ylab="f(x)") # 確率密度曲線
> abline(h=0, v=0, col="blue", lty=3)
> (prob <- pexp(0, rate=2, lower.tail=FALSE)) # 0 以上の確率
[1] 1