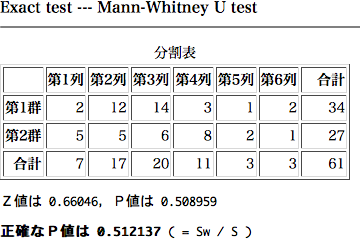
No.14093 Re: 分割表に対するノンパラメトリック検定 【青木繁伸】 2011/01/03(Mon) 20:41
SPSS はよくわからないというか,あなたがどう言うようにこのデータを分析したのかよくわからないのでどうとも言えませんが,カテゴリー 7 は結局どちらの群でも該当がなかったのだから,第 7 カテゴリーを分割表に含めたからおかしな事が起きたんでしょう。まずはそれを省いて実行すべし。
そもそも,元データを対象に検定したら,こんな問題は生じないでしょう。
> x <- c(rep(1:6, c(2, 12, 14, 3, 1, 2)),
+ rep(1:6, c(5, 5, 6, 8, 2, 1)))
> g <- factor(rep(1:2, c(34, 27)))
> wilcox.test(x ~ g)
Wilcoxon rank sum test with continuity correction
data: x by g
W = 415, p-value = 0.5138
alternative hypothesis: true location shift is not equal to 0
警告メッセージ:
In wilcox.test.default(x = c(1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, :
タイがあるため,正確な p 値を計算することができません
> wilcox.test(x ~ g, correct=FALSE)
Wilcoxon rank sum test
data: x by g
W = 415, p-value = 0.509
alternative hypothesis: true location shift is not equal to 0
警告メッセージ:
In wilcox.test.default(x = c(1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, :
タイがあるため,正確な p 値を計算することができません
> library(exactRankTests) # ★★★★★ これが一番お勧めでしょう
> wilcox_test(x~g, distribution="exact")
Exact Wilcoxon Mann-Whitney Rank Sum Test
data: x by g (1, 2)
Z = -0.6605, p-value = 0.5121
alternative hypothesis: true mu is not equal to 0
以下の実行例は http://aoki2.si.gunma-u.ac.jp/exact/utest/getpar.html にて