No.12678 Re: 量的な説明変数が分からないので,ダミー変数でグループを作る. 【yuki】 2010/05/22(Sat) 00:21
画像を添付し忘れていました.すみません.
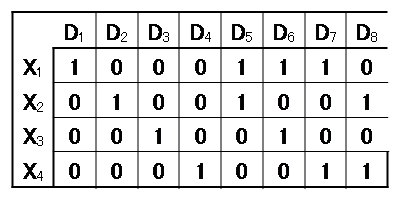
No.12678 Re: 量的な説明変数が分からないので,ダミー変数でグループを作る. 【yuki】 2010/05/22(Sat) 00:21
画像を添付し忘れていました.すみません.
No.12685 Re: 量的な説明変数が分からないので,ダミー変数でグループを作る. 【波音】 2010/05/22(Sat) 18:21
> 量的な説明変数が一つしか,えられていません
説明変数に量的な変数(連続型の変数)と質的な変数(カテゴリカル型の変数)が混在していても何ら問題はありません。
> 選択されたダミー変数が分けるグループに,説明力があると考えます.つまり,グループ内の変数間に説明力の差はないものとして考えます.さらに,事前に想定していた要因(同グループに共通して存在すると考えられた)と照らし合わせ,要因を特定します.
というアプローチが私にはよく理解できなかったのですが,
> 量的な説明変数と一緒に,ステップワイズ法で変数選択を行います.
というのは一般的なものではないでしょう。
なおダミー変数を用いた回帰分析(重回帰分析)は数量化I類に等しく,一般線形モデルでいえば分散分析のことです。要するにダミー変数を用いた回帰というのは分散分析のことなのです。
yukiさんのような説明変数に連続型とカテゴリカル型が混在している場合のモデルを一般線形モデルでは共分散分析モデルといいます(典型的な教科書に載っている共分散分析のことです)。
No.12689 Re: 量的な説明変数が分からないので,ダミー変数でグループを作る. 【yuki】 2010/05/22(Sat) 23:00
波音さん。ご回答ありがとうございます。
>> 選択されたダミー変数が分けるグループに,説明力があると考えます.つまり,グループ内の変数間に説明力の差はないものとして考えます.さらに,事前に想定していた要因(同グループに共通して存在すると考えられた)と照らし合わせ,要因を特定します.
>というアプローチが私にはよく理解できなかったのですが,
例えばですが,添付画像のD5にあたるグループには,特定の要因があるという仮説が考えられた場合,ステップワイズでD5が選択されれば,この要因が従属変数に対して説明力を持っていると考えます。
医療関係で具体的な例を考えますと,従属変数を被験者X1〜X4に対する特定の検査結果と考えます。X1とX2は,検査方法が他の被験者と異なっていたため,これが検査結果に影響を与える可能性があるという仮説がたてられます。
このような文脈でD5が選択されればこの仮説が立証されるのではないか,と考えたのです。検査手法によってどの程度検査結果がことなるのか数量的な説明変数が用意できればそれにこしたことはないのですが,苦肉の策としてダミー変数でグループ化をしてみたのです。
私の理解が十分でないため,説明が下手でもうしわけありません。
教えていただいた共分散分析を考えてみます。
No.12691 Re: 量的な説明変数が分からないので,ダミー変数でグループを作る. 【波音】 2010/05/23(Sun) 00:25
> ステップワイズでD5が選択されれば,
ダミー変数について変数選択を行うということは,カテゴリカル型変数の水準を選択するということで,これは大変におかしな作業です。例えば,性別というカテゴリカル型の変数は男性と女性という2つの水準を持っており,
SEX = {male, male, female, femal}
これをダミー変数で表現するとなると
DUM1 = {0, 0, 1, 1}
DUM2 = {1, 1, 0, 0}
と表せますが,これを
Y = DUM1 + DUM2
Y = DUM1
Y = DUM2
の どれが最も応答変数Yを説明するモデルかということを選ぼうとしているわけです。通常,ダミー変数はカテゴリカル型変数の水準の数だけ用意されますが,実 際の解析には任意の1つのダミー変数を削除します。上の例だとDUM1だけ,あるいはDUM2だけでも男性か女性かを識別できるからです。
したがって,Y = DUM1 + DUM2は問題外で,Y = DUM1もY = DUM2もどの水準をベースライン(基準)としておいたかという違いだけで,実質的に全く同じモデルです。つまり,変数選択は意味のない作業であるということです。
以 下の解析例は3群のデータの平均値を比較するもの(分散分析モデル,ダミー変数を用いた重回帰,数量化I類)ですが,DUM1からDUM3のどれをベース ラインとしても(削除しても)結局は同じ結果(予測値)が得られます。もっともダミー変数を用意しなくてもRではfactor()で作られた因子型(カテ ゴリカル型)の変数を直接使うことができますが(^_^;)
> y <- c(12, 13, 10, 10, 3, 3, 1, 5, 22, 19, 18, 20)
> g <- rep(c(1,2,3), c(4,4,4))
> D1 <- rep(c(1,0,0), c(4,4,4))
> D2 <- rep(c(0,1,0), c(4,4,4))
> D3 <- rep(c(0,0,1), c(4,4,4))
> mydata <- data.frame(Y=y, group=g, DUM1=D1, DUM2=D2, DUM3=D3)
> mydata
Y group DUM1 DUM2 DUM3
1 12 1 1 0 0
2 13 1 1 0 0
3 10 1 1 0 0
4 10 1 1 0 0
5 3 2 0 1 0
6 3 2 0 1 0
7 1 2 0 1 0
8 5 2 0 1 0
9 22 3 0 0 1
10 19 3 0 0 1
11 18 3 0 0 1
12 20 3 0 0 1
> result <- lm(Y ~ DUM2 + DUM3, data=mydata)
> result2 <- lm(Y ~ DUM1 + DUM2, data=mydata)
> result3 <- lm(Y ~ DUM1 + DUM3, data=mydata)
> predict(result)
1 2 3 4 5 6 7 8 9 10 11 12
11.25 11.25 11.25 11.25 3.00 3.00 3.00 3.00 19.75 19.75 19.75 19.75
> predict(result2)
1 2 3 4 5 6 7 8 9 10 11 12
11.25 11.25 11.25 11.25 3.00 3.00 3.00 3.00 19.75 19.75 19.75 19.75
> predict(result3)
1 2 3 4 5 6 7 8 9 10 11 12
11.25 11.25 11.25 11.25 3.00 3.00 3.00 3.00 19.75 19.75 19.75 19.75
● 「統計学関連なんでもあり」の過去ログ--- 043 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る