No.11199 Re: loglinear model について 【波音】 2009/11/09(Mon) 09:51
> Fijとuが既知なはずなので,
全平均(切片,定数項)もパラメータの1つとして推定されることになります。観測度数(応答変数)についても,対数線形モデルを解析することで予測するという考え方ですから,どちらも母数が既知であるとはいえないでしょう。
> パラメータの数は「主効果の数+交互作用(選択肢と意向の組み合わせ分)の数」
基本的な考え方はそうですが,より正確にいえばある説明変数(カテゴリカル型)の水準数が,例えば3つである場合,いずれかの水準がベースラインとして扱われますから,ある主効果について推定するパラメータ数は3-1=2(水準数-1)ということになります。
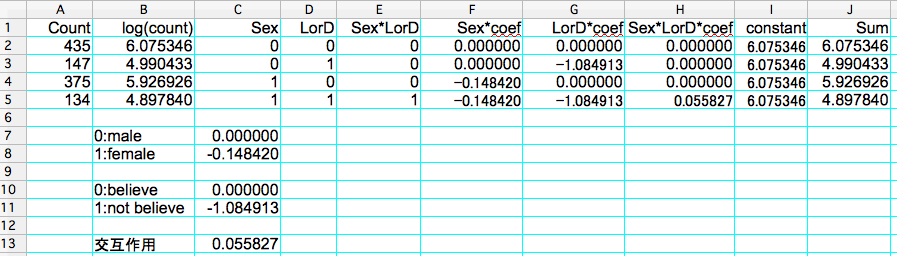
もし複雑な解析で不安ならば,仮のデータを用いて確認してみると良いと思います。渡邉ほか訳『カテゴリカルデータ解析入門』サイエンティスト社(2005)p203の表6.1のデータを参照(以下はRを用いてポアソン回帰モデルを解析した例)。# 観測度数Countと性別Sexと生死観LorDを用意する
Count <- c(435, 147, 375, 134)
Sex <- c("male", "male", "female", "female")
LorD <- c("belive", "not belive", "belive", "not belive")
# factor()を使ってカテゴリカル型であることを指定する
# 引数levelsは水準の順位を指定するものである
Sex <- factor(Sex, levels=c("male", "female"))
LorD <- factor(LorD, levels=c("belive", "not belive"))
# glm()を用いてモデル解析
# SexとLorDを*でつないでいるのは,飽和モデルであることを表す
# 引数familyではポアソン分布に従うことを仮定している
model <- glm(Count ~ Sex * LorD, family=poisson)
(R
を用いて解析するのか分かりませんが^^;)dummy.coef()を使うと,推定されたパラメータが何であるのか一目瞭然です。Rのglm()という
関数では,デフォルトで第1水準がベースラインとして扱われるので,Sex, maleが0,LorD,
beliveが0とされています。交互作用項については,maleとbeliveをベースラインとしているのでこの水準が含まれる組合せは,やはり0と置
かれます。
結局,推定されたパラメータは切片を含めて4つということです。> dummy.coef(model)
Full coefficients are
(Intercept): 6.075346
Sex: male female
0.00000 -0.14842
LorD: belive not belive
0.000000 -1.084913
Sex:LorD: male:belive female:belive male:not belive female:not belive
0.00000000 0.00000000 0.00000000 0.05582722