No.11056 Re: 二項分布におけるp値の範囲推定 【青木繁伸】 2009/10/13(Tue) 18:58
有限母集団からの標本サイズ
http://aoki2.si.gunma-u.ac.jp/R/finite.html
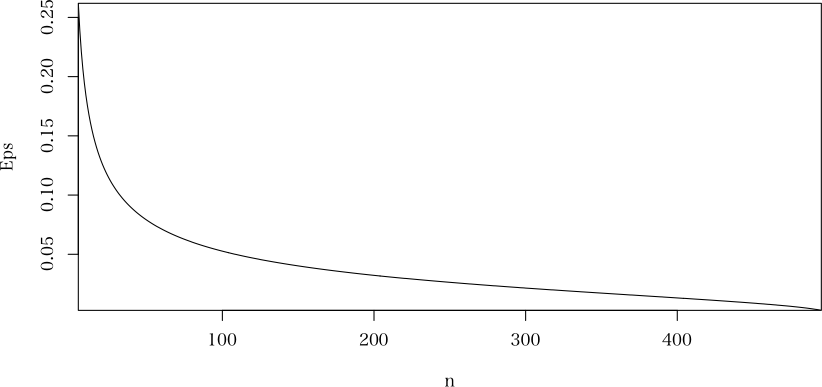
にある,プログラムで,母比率が0.1である母集団500から,標本を5〜495取り出したとき,信頼度0.95での精度(誤差;Eps)を求めてみます。Epsは信頼区間の幅の半分です。
> n <- 5:495
> Eps <- sapply(n, function(n) finite(n=n, N=500, p=0.1, conf.level=0.95)$epsilon)
> plot(n, Eps, type="l", xaxs="i", yaxs="i")
> cbind(n, Eps)
n Eps
[1,] 5 0.261900599
[2,] 6 0.238836058
[3,] 7 0.220886134
[4,] 8 0.206428300
[5,] 9 0.194424629
[6,] 10 0.184251989
[7,] 11 0.175499286
[8,] 12 0.167856381
途中省略
[486,] 490 0.003743209
[487,] 491 0.003538984
[488,] 492 0.003384721
[489,] 493 0.003156828
[490,] 494 0.002914067
[491,] 495 0.002652827
図は,クリックすると原寸表示されます。
し かし,あなたが知りたいのは,不良品500個の中の要因Aによる不良割合の信頼区間ではなく,無限母集団における不良割合の信頼区間ではないですか?つま り,500というのは母集団ではなく,取りあえず標本を採るためにとっておいただけのものということではないのですか。500個たまった中から100個取 り出して計算しようというのはおかしなことです。最初から100個を調べて要因Aによる不良品の信頼区間を調べようという計画を立てたら,100個たまっ たときにすぐに調査と計算をすればよかったのです。漫然と500個たまるまで待って,その中から100個を取り出すのは,残り400個をとるために使った 時間と計算に使われなかった400個のデータが無駄になるのです。時間を無駄にしたくないなら,そのときまでに得られた全データ(500個)を使えばよい だけです。精度も高くなりますし。