No.10131 Re: 多変量回帰分析と主成分分析 【波音】 2009/06/18(Thu) 17:43
X = {x1, x2, x3}という変数群に対して主成分を求め,それを説明変数としてy1 = zx, y2 = zx, y3 = zxとすることはかなり予測精度が落ちるので好ましい方法ではないことが分かりました。
> y1 <- Y[,1]
> y2 <- Y[,2]
> y3 <- Y[,3]
> summary(lm(y1 ~ zx))
> summary(lm(y2 ~ zx))
> summary(lm(y3 ~ zx))
Rで多変量回帰を行う関数を見つけられなかったのでLISREL(http://www.ssicentral.com/)を用いて多変量回帰モデルとして解析。多変量回帰モデルの解析によって得られたy1, y2, y3それぞれの重回帰モデルの予測精度と比較してみる。
# 多変量回帰モデルから得られたy1の予測式
lm.y1 <- function(x1, x2, x3) 65.62 + 0.13*x1 + 0.30*x2 - 0.16*x3
# lm(y1 ~ zx)より得られたy1の予測式
pca.y1 <- function(zx) 78.801 + 0.293*zx
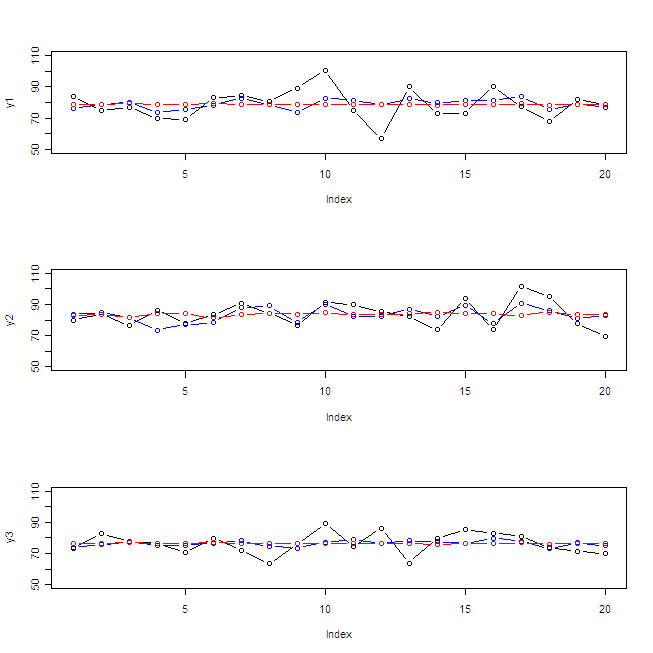
# 実測値y1のプロット
plot(y1, type="b", ylim=c(50, 110))
# 多変量回帰の予測値プロット
points(lm.y1(x1, x2, x3), type="b", col="blue")
# 主成分を説明変数としたモデルの予測値プロット
points(pca.y1(zx), type="b", col="red")
以下,y2とy3も同様。
lm.y2 <- function(x1, x2, x3) 93.80 - 0.21*x1 + 0.38*x2 - 0.36*x3
pca.y2 <- function(zx) 83.7509 - 0.8128*zx
plot(y2, type="b", ylim=c(50, 110))
points(lm.y2(x1, x2, x3), type="b", col="blue")
points(pca.y2(zx), type="b", col="red")
lm.y3 <- function(x1, x2, x3) 61.68 + 0.16*x1 + 0.14*x2 - 0.0098*x3
pca.y3 <- function(zx) 76.4062 + 0.3165*zx
plot(y3, type="b", ylim=c(50, 110))
points(lm.y3(x1, x2, x3), type="b", col="blue")
points(pca.y3(zx), type="b", col="red")