No.07904 Re: 一般線形モデルの固定因子について 【波音】 2008/10/10(Fri) 14:38
> 重回帰は従属変数が連続型で,独立変数に性別(2値の変数)などは投入することがある
一般線形モデルにおいて,独立変数の数と型によっていくつかのモデルが考えられます。それをまとめてみましょう(ちなみに一般線形モデルでは従属変数は連続型に限ります)。
従属変数をY,独立変数をX1, X2とすると,
Y = X1 (X1はカテゴリカル型) ⇒ 1要因の分散分析モデル
Y = X1 + X2 + X1*X2(X1,X2は共にカテゴリカル型) ⇒ 2要因の分散分析モデル
Y = X1 (X1は連続型) ⇒ 単回帰分析モデル
Y = X1 + X2 + X1*X2(X1,X2は共に連続型) ⇒ 重回帰分析モデル
Y = X1 + X2 (X1はカテゴリカル型,X2は連続型) ⇒ 共分散分析モデル
といったモデルが代表格です。したがって,独立変数に性別などの変数を投入する場合,それは分散分析モデルになるわけです。もし連続型の変数が混在していれば,それは共分散分析モデルなのです。
> 従属変数を血圧にして,独立変数を職業のダミー変数にして(下記表のように)解析を行うこともあると思っていいですか?
実際に例データで解析してみましょう。
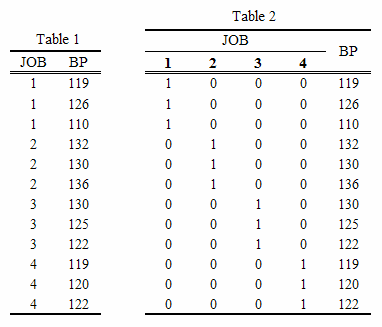
まずJOB(職業)はカテゴリカル型であるので,カテゴリカル型の変数としてコンピュータに認識させて分析します。添付図のTable1のデータのまま解析します。
# JOBに職業を表すデータを代入する
> JOB <- rep(c(1, 2, 3, 4), c(3, 3, 3, 3))
> JOB <- as.factor(JOB) # カテゴリカル型として指定
> JOB #中身を確認すると,4水準のカテゴリカル型データになっている
[1] 1 1 1 2 2 2 3 3 3 4 4 4
Levels: 1 2 3 4
# BPに血圧(収縮期血圧)のデータを代入
> BP <- c(119, 126, 110, 132, 130, 136, 130, 125, 122, 119, 120, 122)
> BP # 中身を確認すると,これは連続型である
[1] 119 126 110 132 130 136 130 125 122 119 120 122
> model <- lm(BP ~ JOB) # 関数lm()を用いてモデル解析
> summary(model2) # 係数表の出力
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 118.333 2.774 42.660 1.01e-10 ***
JOB2 14.333 3.923 3.654 0.00646 **
JOB3 7.333 3.923 1.869 0.09850 .
JOB4 2.000 3.923 0.510 0.62393
続
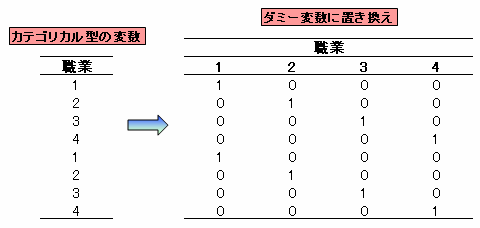
いて,今度は添付図Table2のデータで分析してみます。これはカテゴリカル型の変数を,自分でダミー変数に置き換えて分析してやるという方法です。
JOB1, JOB2 , JOB3,
JOB4は2値データですが,2値データは間隔尺度として扱うことができるので,このように変換して分析することは重回帰分析を行うことと同義なわけで
す。
# ダミー変数を用意する。用意するのはJOB1を除いたJOB2-4までの3つでよい。
> JOB2 <- rep(c(0, 1, 0, 0), c(3, 3, 3, 3))
> JOB3 <- rep(c(0, 0, 1, 0), c(3, 3, 3, 3))
> JOB4 <- rep(c(0, 0, 0, 1), c(3, 3, 3, 3))
# JOB2-4の中身を確認。これは全て連続型として扱える。
> JOB2
[1] 0 0 0 1 1 1 0 0 0 0 0 0
> JOB3
[1] 0 0 0 0 0 0 1 1 1 0 0 0
> JOB4
[1] 0 0 0 0 0 0 0 0 0 1 1 1
> model2 <- lm(BP ~ JOB2 + JOB3 + JOB4)
> summary(model2)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 118.333 2.774 42.660 1.01e-10 ***
JOB2 14.333 3.923 3.654 0.00646 **
JOB3 7.333 3.923 1.869 0.09850 .
JOB4 2.000 3.923 0.510 0.62393
係
数表(Coefficients:の部分)を見ると,どちらも同じ係数が得られていることが確認できるでしょう。先ほどのスレッドでも述べたように,基本
は「カテゴリカル型は全てダミー変数に置き換えられて解析されている」ということで,多くのソフトウェアではそういう手間を省けるように,Rでいうところ
のas.factor()という関数があるわけです。
SPSSにそのような機能がなければ,自分でダミー変数を用意して分析するしかないということでもあります。だから,
> SPSSでは一般線形モデルで「この変数はカテゴリーです」と指定するところがないので,自分でダミー変数を作って,独立変数に投入してもよいでしょうか?
という問いに対しては「その通りです」ということがいえるわけです。