No.04854 ExcelでLinear Regression 【みずはら】 2007/11/29(Thu) 04:38
ExcelでLinear Regressionを実行したら,不思議な結果になりました。R Squareがいいほうの結果が悪いです。コメントをお願いいたします。
データセット1:X1 X2 X3 X4 Y Predicted Y Error Rate
78 56 53 58 70 62.82344642 10.3%
47 53 58 70 48 53.66028825 11.8%
55 58 70 48 49 63.21386332 29.0%
53 70 48 49 58 57.50818974 0.8%
61 48 49 58 54 55.52569193 2.8%
61 49 58 54 57 58.99941356 3.5%
49 58 54 57 50 55.38364165 10.8%
62 54 57 50 51 60.24938324 18.1%
54 57 50 51 53 56.14150715 5.9%
56 50 51 53 60 55.67840865 7.2%
53 51 53 60 52 54.7340516 5.3%
58 53 60 52 65 59.65173695 8.2%
70 60 52 65 57 59.99547179 5.3%
48 52 65 57 68 57.60892285 15.3%
49 65 57 68 56 56.03137507 0.1%
58 57 68 56 60 62.27547949 3.8%
54 68 56 60 59 58.60164683 0.7%
57 56 60 59 62 58.95776167 4.9%
50 60 59 62 53 56.91425006 7.4%
51 59 62 53 80 59.10927432 26.1%
53 62 53 80 55 53.93619546 1.9%
このデータセットのR squareが0.129,Fが0.596,Significance Fが0.67.
尚,Error Rateは(Predicted Y-Y)/Y です。
データセット2:X1 X2 X3 X4 Y Predicted Y Error Rate
224 61 66 279 340 233.7142237 31.3%
43 66 279 340 58 69.87720075 20.5%
66 279 340 58 128 79.17177353 38.1%
133 340 58 128 77 134.3868679 74.5%
50 58 128 77 73 88.49919669 21.2%
57 128 77 73 110 89.21708667 18.9%
273 77 73 110 382 280.6654 26.5%
52 73 110 382 83 78.55477671 5.4%
76 110 382 83 82 101.7323733 24.1%
61 382 83 82 94 69.04391456 26.5%
66 83 82 94 61 100.3482963 64.5%
279 82 94 61 326 286.7712393 12.0%
340 94 61 326 284 330.1090411 16.2%
58 61 326 284 109 84.52165499 22.5%
128 326 284 109 124 128.0355474 3.3%
77 284 109 124 131 90.01833824 31.3%
73 109 124 131 66 102.0406385 54.6%
110 124 131 66 118 135.0151266 14.4%
382 131 66 118 284 370.4401716 30.4%
83 66 118 284 70 109.4519451 56.4%
82 118 284 70 70 108.3851871 54.8%
このデータセットのR squareが0.780,Fが14.24,Significance Fがほぼ0.
エラーレートから見ると,明らかにデータセット1のほうがいいです。
僕が思うには,R squareが大きいほうはRegression Modelがよくデータを表していることを意味しています。でも,結果が正反対です。何が間違っているでしょうか?
ご教授願います。
No.04856 Re: ExcelでLinear Regression 【青木繁伸】 2007/11/29(Thu) 09:01
変数間の散布図を描いてみることをお勧めします
データセット2は特にそうですが,重回帰モデルを適用するにはかなり問題のあるデータであるということが分かると思います。
ステップワイズ法で分析しようとすると,一つめの独立変数を決めようとする段階で「モデルに追加できる変数はない。。。」などと言う結果になります。
不適切な重回帰モデル同士を比較することは意味がありません。
No.04857 Re: ExcelでLinear Regression 【kai】 2007/11/29(Thu) 09:06
Rsquareはモデルでデータがどれだけ説明しているかを表す指標ですが,注意点として,データ(ここではY)の範囲が広くなると同じ程度のバラツキでも決定係数は良くなる性質があります.
それぞれのデータのYのCV値を計算するとデータセット1は13%に対してデータセット2は72%になります.データセット2のRsquareの値が大きくなっているのはYの範囲が大きい事が原因です.
予測の精度に関してはRsquareではなくRMSE(誤差の標準偏差)を使用した方がよいでしょう.
No.04860 Re: ExcelでLinear Regression 【青木繁伸】 2007/11/29(Thu) 10:01
訂正
データセット2は,変数選択では X1 のみが選択されます
データセット2は,外れ値とは行かないまでも他と比べて大きい数値を持つものがいくつかあるため,重回帰分析としては不適切でしょう。
No.04861 Re: ExcelでLinear Regression 【青木繁伸】 2007/11/29(Thu) 10:11
予測値と実測値の比較図です
データセット1 において,予測値と実測値の相関係数は 0.3600417 で,その二乗が決定係数 R^2 = 0.1296300 です
データセット2 において,予測値と実測値の相関係数は 0.8836131 で,その二乗が決定係数 R^2 = 0.7807721 です
データセット2において,予測値と実測値の相関の程度が本当に 0.9 ほどもあるのかというところが,キーポイントでしょう(実際に計算するとそうなるんですけどね)
たとえば,スピアマンの順位相関係数を計算してみると 0.5328136 で,ちなみにそれを二乗してみると 0.2838904 です。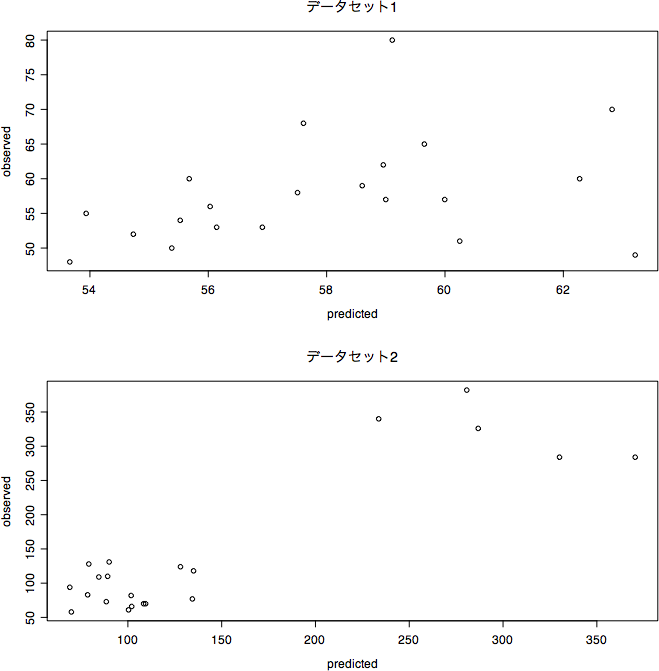
No.04878 Re: ExcelでLinear Regression 【みずはら】 2007/11/30(Fri) 04:13
貴重な時間を割いていただいて,誠にありがとうございます。
ご指摘のとおりだと思います。統計学って本当に面白くて,奥深いですね。でも,一歩間違うと,とんでもないところまでいきます。
ありがとうございました。
● 「統計学関連なんでもあり」の過去ログ--- 041 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る