85 すでに取り上げた話題ではあるが 青木繁伸 2003/01/14 (火) 21:38
326 Re: すでに取り上げた話題ではあるが マスオ 2003/02/10 (月) 19:44
333 Re^2: すでに取り上げた話題ではあるが 2003/02/11 (火) 21:30
328 Re^2: すでに取り上げた話題ではあるが 青木繁伸 2003/02/10 (月) 21:13
95 Re: すでに取り上げた話題ではあるが 青木繁伸 2003/01/15 (水) 17:49
325 Re^2: すでに取り上げた話題ではあるが マスオ 2003/02/10 (月) 19:40
327 Re^3: すでに取り上げた話題ではあるが 青木繁伸 2003/02/10 (月) 21:12
97 Re^2: すでに取り上げた話題ではあるが 青木繁伸 2003/01/15 (水) 17:57
100 Re^3: すでに取り上げた話題ではあるが 青木繁伸 2003/01/16 (木) 15:23
106 Re^4: すでに取り上げた話題ではあるが 伊達 2003/01/16 (木) 23:23
108 Re^5: すでに取り上げた話題ではあるが 青木繁伸 2003/01/17 (金) 00:33
119 Re^6: すでに取り上げた話題ではあるが ひの 2003/01/17 (金) 21:42
147 Re^7: すでに取り上げた話題ではあるが 青木繁伸 2003/01/22 (水) 10:25
151 Re^8: すでに取り上げた話題ではあるが 青木繁伸 2003/01/22 (水) 12:08
167 Re^9: すでに取り上げた話題ではあるが 2003/01/23 (木) 19:07
170 Re^10: すでに取り上げた話題ではあるが 青木繁伸 2003/01/23 (木) 20:40
171 Re^11: すでに取り上げた話題ではあるが 青木繁伸 2003/01/23 (木) 20:51
169 Re^10: すでに取り上げた話題ではあるが 青木繁伸 2003/01/23 (木) 20:05
150 Re^9: すでに取り上げた話題ではあるが 青木繁伸 2003/01/22 (水) 11:17
148 Re^8: すでに取り上げた話題ではあるが 青木繁伸 2003/01/22 (水) 11:01
120 Re^7: すでに取り上げた話題ではあるが 青木繁伸 2003/01/17 (金) 22:16
88 Re: すでに取り上げた話題ではあるが 青木繁伸 2003/01/14 (火) 23:13
90 Re^2: すでに取り上げた話題ではあるが sb812109 2003/01/14 (火) 23:36
91 Re^3: すでに取り上げた話題ではあるが 青木繁伸 2003/01/15 (水) 13:14
92 Re^4: すでに取り上げた話題ではあるが sb812109 2003/01/15 (水) 14:27
107 Re^5: すでに取り上げた話題ではあるが 伊達 2003/01/16 (木) 23:36
| 85. すでに取り上げた話題ではあるが 青木繁伸 2003/01/14 (火) 21:38 |
Excel には,いろいろ問題があると言うことの蒸し返し |
| 326. Re: すでに取り上げた話題ではあるが マスオ 2003/02/10 (月) 19:44 |
> Excel には,いろいろ問題があると言うことの蒸し返し |
| 333. Re^2: すでに取り上げた話題ではあるが 2003/02/11 (火) 21:30 |
> さて,タイトルはrepeated measures ANOVAになっていますが,普通の二元配置分散分析で,Sphericityについては何も出力されていませんでした. |
| 328. Re^2: すでに取り上げた話題ではあるが 青木繁伸 2003/02/10 (月) 21:13 |
> MSやExcelだけの問題ではないような気がしています. |
| 95. Re: すでに取り上げた話題ではあるが 青木繁伸 2003/01/15 (水) 17:49 |
> 乱数は 32768 種の値しか持たないとか,統計関数の精度が悪いとか。 |
| 325. Re^2: すでに取り上げた話題ではあるが マスオ 2003/02/10 (月) 19:40 |
こんにちは.相変わらずExcelで統計やってるマスオです. |
| 327. Re^3: すでに取り上げた話題ではあるが 青木繁伸 2003/02/10 (月) 21:12 |
> こんにちは.相変わらずExcelで統計やってるマスオです. |
| 97. Re^2: すでに取り上げた話題ではあるが 青木繁伸 2003/01/15 (水) 17:57 |
エクセルは非道いというページを作ります |
| 100. Re^3: すでに取り上げた話題ではあるが 青木繁伸 2003/01/16 (木) 15:23 |
以下について,マイクロソフトの見解が分かりました。 |
| 106. Re^4: すでに取り上げた話題ではあるが 伊達 2003/01/16 (木) 23:23 |
「エクセルは非道い」ですとWeb検索では引っかからない可能性がありませんか。。。 |
| 108. Re^5: すでに取り上げた話題ではあるが 青木繁伸 2003/01/17 (金) 00:33 |
> 「エクセルは非道い」ですとWeb検索では引っかからない可能性がありませんか。。。 |
| 119. Re^6: すでに取り上げた話題ではあるが ひの 2003/01/17 (金) 21:42 |
> ただ,誰か個人が書いたプログラムだとくそみそにけなされるような恥ずかしいバグなのに,マイクロソフトだと誰も責めないというのが情けない。と思ったわけです。 |
| 147. Re^7: すでに取り上げた話題ではあるが 青木繁伸 2003/01/22 (水) 10:25 |
AVEDEV という関数がありまして, |
| 151. Re^8: すでに取り上げた話題ではあるが 青木繁伸 2003/01/22 (水) 12:08 |
GEOMEAN |
| 167. Re^9: すでに取り上げた話題ではあるが 2003/01/23 (木) 19:07 |
> CORREL |
| 170. Re^10: すでに取り上げた話題ではあるが 青木繁伸 2003/01/23 (木) 20:40 |
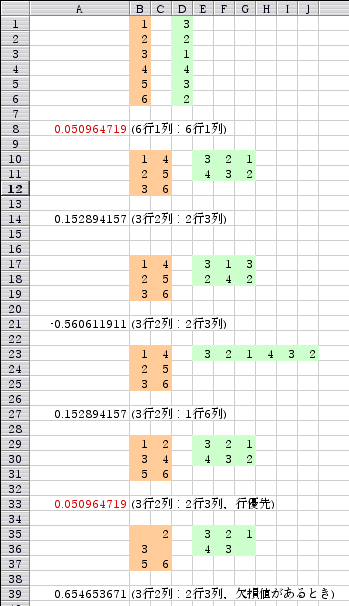
データがそれぞれ1列に書かれているときでも,いくつかのセルが空で,デー達意を構成していないときにもエラーにならない。 |
| 171. Re^11: すでに取り上げた話題ではあるが 青木繁伸 2003/01/23 (木) 20:51 |
なるほどね。 |
| 169. Re^10: すでに取り上げた話題ではあるが 青木繁伸 2003/01/23 (木) 20:05 |
> 揚げ足取りになるようですが, |
| 150. Re^9: すでに取り上げた話題ではあるが 青木繁伸 2003/01/22 (水) 11:17 |
COVAR |
| 148. Re^8: すでに取り上げた話題ではあるが 青木繁伸 2003/01/22 (水) 11:01 |
ちなみに,英文では, |
| 120. Re^7: すでに取り上げた話題ではあるが 青木繁伸 2003/01/17 (金) 22:16 |
> しかし,EXCELのヘルプには「この式で計算します」と明記してあるわけですから,「バグ」とは言えないでしょう。むしろちゃんと計算できたらヘルプの方が嘘になる。数式が間違っているわけでも,プログラムが間違っているわけでもない。ある条件で計算が破たんするタコなアルゴリズムが使われているだけのこと。 |
| 88. Re: すでに取り上げた話題ではあるが 青木繁伸 2003/01/14 (火) 23:13 |
これは,さっき気づいたこと |
| 90. Re^2: すでに取り上げた話題ではあるが sb812109 2003/01/14 (火) 23:36 |
数は力。力は正義。 |
| 91. Re^3: すでに取り上げた話題ではあるが 青木繁伸 2003/01/15 (水) 13:14 |
> 数は力。力は正義。 |
| 92. Re^4: すでに取り上げた話題ではあるが sb812109 2003/01/15 (水) 14:27 |
基準が確立しそうな時に,似て非なる基準をぶつけて,強引に乗っ取ってしまう |
| 107. Re^5: すでに取り上げた話題ではあるが 伊達 2003/01/16 (木) 23:36 |
しかし…, pearson関数に関しての青木先生の指摘には,椅子から転げ落ちた後に, |
● 「統計学関連なんでもあり」の過去ログ--- 023 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る
{kind=link}