まず最初に,分析に使用するデータを準備する。各アイテム変数を,「その変数が持つカテゴリー数 − 1」個のダミー変数に変換する(表 2 参照)。
例えば,あるアイテム変数が 3 個のカテゴリーを持つときは 2 個のダミー変数をあてる。アイテム変数の値が 1 のときは,2 個のダミー変数は 0, 0 とし,2 のときは 1, 0 とし,3 のときは 0, 1 とする。
|
|
***** 判別係数 *****
| 判別係数 | 標準化判別係数 | ||||
| $d_{11}$ | -5.52441 | -2.70640 | |||
| $d_{12}$ | -9.87342 | -4.36619 | |||
| $d_{21}$ | -2.20976 | -1.04169 | |||
| $d_{22}$ | -1.01085 | -0.47652 | |||
| 定数項 | 6.11358 | ||||
判別係数の解釈は以下のようになる。
元のアイテム変数 $x_{i}$ は,2 個のダミー変数 $d_{i1}$ と $d_{i2}$ を使って表現されている($i = 1, 2$)。それぞれのダミー変数に対する判別係数を $b_{i1}$ ,$b_{i2}$ とすると,判別値は $\hat{y} = d_{11}\cdot b_{11} + d_{12}\cdot b_{12} + d_{21}\cdot b_{21} + d_{22}\cdot b_{22} + 定数項$ であらわされる。
$x_{1}$ が 1 という値を取るときは,$d_{11} = 0$,$d_{12} = 0$ であるから,判別値に寄与する値は $0\cdot 6.74375 + 0\cdot 17.225 = 0 $である。
$x_{1}$ が 2 という値を取るときは,$d_{11} = 1$,$d_{12} = 0$ であるから,判別値に寄与する値は $1\cdot (-5.52441) + 0\cdot (-9.87342) = -5.52441$ である。すなわち,この場合は $x_{1} = 1$ の場合に比べて判別値は $5.52441$ 小さくなる。
$x_{1}$ が 3 という値を取るときは,$d_{11} = 0$,$d_{12} = 1$ であるから,判別値に寄与する値は $0\cdot (-5.52441) + 1\cdot (-9.87342) = -9.87342$ である。すなわち,この場合は $x_{1} = 1$ の場合に比べて判別値は $9.87342$ 小さくなる。
標準化判別係数の大きさからいうと,予測をするために最も重要なのは $d_{12}$ であり,次いで $d_{11}$ である(これらに対する $P$ 値が小さいので,これらの係数が 0 でないといってよいことがわかる)。$d_{22}$ ,$d_{21}$ はそれらに比べて予測という観点からはあまり重要ではないことがわかる。
***** 各ケースの判別結果 *****
|
判別値は数量化 I 類による結果比例する。 結局,判別係数の値とノーマライズドカテゴリースコアの値は異なるように見えるが,定数項を含めた調整の後では全く等価な判別値を与える重みであることが分かる。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
***** 判別結果総括表 *****
|
第 1 群の 8 例中 7 例,第 2 群の 7 例中 6 例が正しく判別できている。正判別率は正しく判別された数(7+6)を全体の数 15 で割った割合として求めてある。 数量化 II 類の結果と全く同じである。 |
|||||||||||||||||||||||||||||||||||||||||||||||
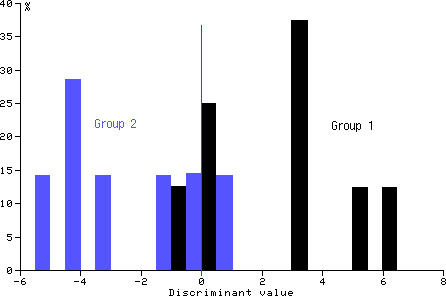
***** 二群の判別図 *****
|