混合分布に従う 1 変数データの生成 Last modified: Aug 13, 2009
目的
指定した平均値ベクトル mu と標準偏差ベクトル sigma を持つ母集団から,比率ベクトル prob で抽出される n 個の混合正規乱数を発生させる
使用法
mix1(n, mu, sigma, prob=rep(1/length(mu),length(mu)))
引数
n データ数
mu 平均値ベクトル
sigma 標準偏差ベクトル
prob 抽出割合(デフォルトは均等割合)
プログラムは,基本的には,n1+n2+…+ni=n として,
c(rnorm(n1, mu1, sugma1), rnorm(n2, mu2, sigma2), … , rnorm(ni, mui, sigmai))
を作って,ランダムに取り出すのと同じ。
ソース
インストールは,以下の 1 行をコピーし,R コンソールにペーストする
source("http://aoki2.si.gunma-u.ac.jp/R/src/mix1.R", encoding="euc-jp")
# 指定した平均値ベクトル mu と標準偏差ベクトル sigma を持つ母集団から,比率ベクトル prob で抽出される n 個の混合正規乱数を発生させる
mix1 <- function( n, # データ数
mu, # 平均値ベクトル
sigma, # 標準偏差ベクトル
prob=rep(1/length(mu),length(mu))) # 抽出割合
{
k <- length(mu)
if (k == length(sigma) && k == length(prob)) {
suffix <- sample(k, n, replace=TRUE, prob=prob)
x <- mapply(function(mean, sd) rnorm(n, mean, sd), mu, sigma)
return(list(d=x[cbind(1:n,suffix)], which=suffix))
}
}
使用例
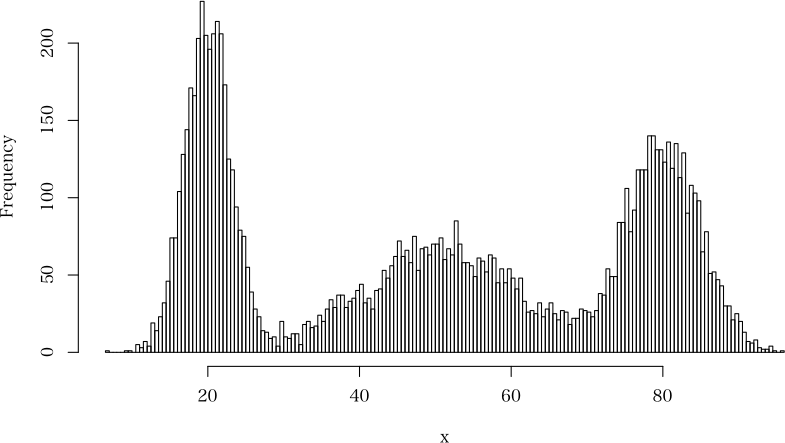
N(50,10^2), N(80,5^2), N(20,3^2) の 3 母集団から,同じ割合で抽出する
> x <- mix1(10000, c(50, 80, 20), c(10, 5, 3))$d # データは要素名 d に入っている
> hist(x, breaks=200, main="")
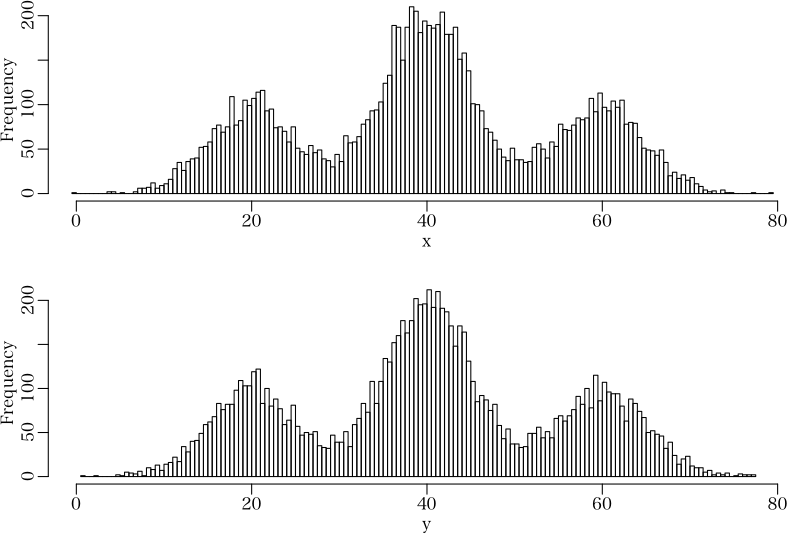
 二通りの考え方でデータ生成したものが同じになることを示す
> old <- par(mar=c(3,4,1,1), mgp=c(1.5,0.5,0))
> layout(matrix(1:2, 2))
> x <- mix1(10000, c(20, 40, 60), c(5, 5, 5), prob=c(1,2,1))$d
> hist(x, breaks=200, main="", xlim=c(0, 80))
> y <- c(rnorm(10000/4, 20, 5), rnorm(10000/2, 40, 5), rnorm(10000/4, 60, 5))
> hist(y, breaks=200, main="", xlim=c(0, 80))
> layout(1)
> par(old)
二通りの考え方でデータ生成したものが同じになることを示す
> old <- par(mar=c(3,4,1,1), mgp=c(1.5,0.5,0))
> layout(matrix(1:2, 2))
> x <- mix1(10000, c(20, 40, 60), c(5, 5, 5), prob=c(1,2,1))$d
> hist(x, breaks=200, main="", xlim=c(0, 80))
> y <- c(rnorm(10000/4, 20, 5), rnorm(10000/2, 40, 5), rnorm(10000/4, 60, 5))
> hist(y, breaks=200, main="", xlim=c(0, 80))
> layout(1)
> par(old)
 直前のページへ戻る E-mail to Shigenobu AOKI
直前のページへ戻る E-mail to Shigenobu AOKI
