sim <- function(rep, n)
{
result <- numeric(rep)
for (i in 1:rep) {
x <- rnorm(n)
y <- rnorm(n)
g <- ifelse(x < -1.5, 1, ifelse(x < -0.5, 2, ifelse(x < 0.5, 3, ifelse(x < 1.5, 4, 5))))
xx <- tapply(x, g, mean)
yy <- tapply(y, g, mean)
result[i] <- cor(xx, yy)
}
result
}
hist(sim(1000, 300))
のような R プログラムを書いてシミュレーションしてみました。
このプログラムは,「相関のない正規変数を300組発生させ,片方の変数を -1.5, -0.5, 0.5 1.5 で層別し,それぞれの層ごとに平均値を求め,もう一方の変数も層ごとに平均値を求め,各層の5組の平均値についてピアソンの相関係数を求める」というものです。その相関係数の分布は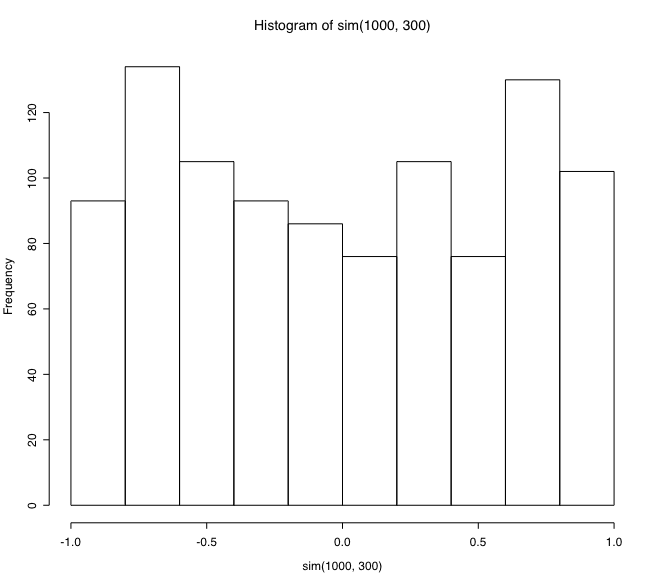
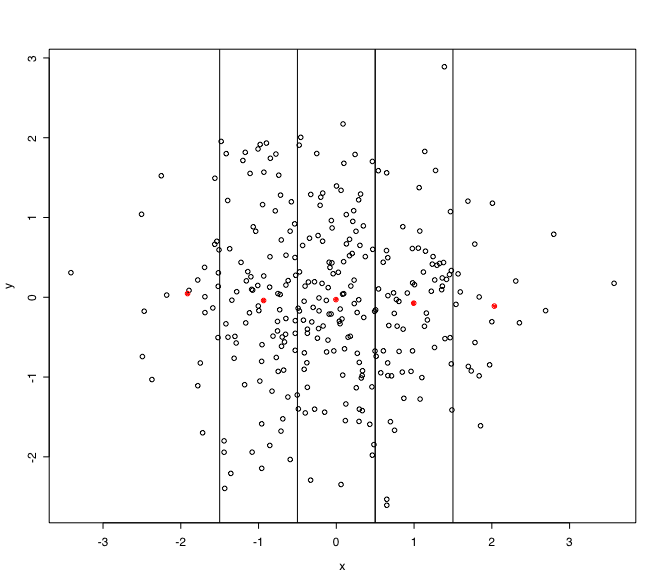
実際のデータ解析においても,全体のデータの散布図と,層別の平均値のプロットを描いて眺めてみると,層別の平均値間の相関係数が高くても,それは何の意味も持っていないと言うことがよく理解できるでしょう。